
Among all the Big Tech companies who are planting flags in the red hot generative AI arms race, I think the most trustworthy one may actually be Meta. Yep, Zuck’s Meta.
I say this because its recently released large language model (LLM), LLaMA (Large Language Model Meta AI), is open sourced and has the clearest set of disclosures around the model’s biases along gender, religion, race, and six other dimensions, compared to other similar LLMs.
Long time readers of Interconnected know that I have deep convictions in open source as both a superior technology development model, and as the best methodology for building trust between users, products, and the regulators who have oversight over them. That’s a long-winded way of saying: sunlight is the best disinfectant. (See my extensive archive of previous writings on this topic.)
Surprisingly or unsurprisingly, Meta, the one company that may have the most “trust deficit” with the American public, is turning to open source to bolster its AI’s trustworthiness. Meanwhile, Meta’s peers are holding their AI models close to the vest as their “secret sauce.” This divergence in approach will play out in a much bigger way as all forms of generative AI applications become more pervasive.

Model Card
What made LLaMA stand out is its “model card.”
A model card is an emerging standard in the machine learning research space, where every newly-trained model publicly shares a set of performance benchmarks, intended use cases, and bias metrics along multiple cultural and demographic dimensions. A model card is usually a high-level summary of this information, similar to an open source project’s readme page or introductory sections of its documentation.
This approach was first articulated in an academic paper in 2018, “Model Cards for Model Reporting”, by Margaret Mitchell, an AI ethics researcher who used to work at Google and now works at Hugging Face (a developer platform specifically for machine learning). Since then, writing a model card as part of the release process of a new machine learning model has become more common. However, the quality of the model cards are all over the place.
LLaMA’s model card is one of the clearest and most transparent ones I’ve seen yet. Among many things, it lays out four model sizes (7B, 13B, 33B, and 65B parameters), an “Intended Use” section, and detailed information on the type of training data that went into building this model. Most importantly, it discloses a set of bias scores along gender, religion, race/color, sexual orientation, age, nationality, physical appearance, and socioeconomic status, where lower the score, less “biased” is the model. Here is how LLaMA scored:
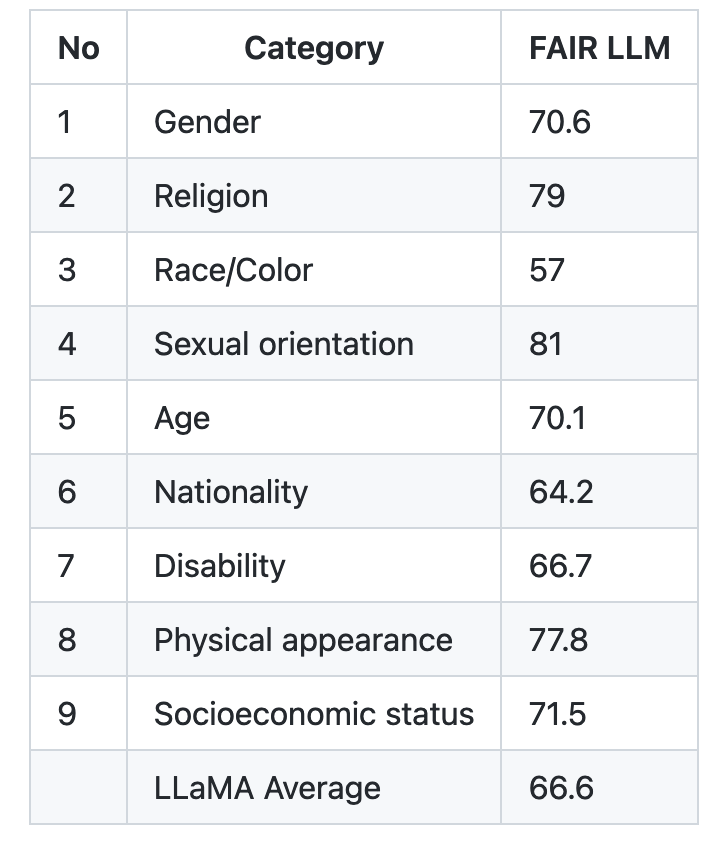
My point of highlighting the biases section of LLaMA’s model card is not to judge how this model is biased towards whom; you can’t take a simplistic reading of these scores to say LLaMA is somehow less “racist” and more “ageist.” The bigger picture is that every machine learning model, especially the many LLMs that are powering a Cambrian explosion of chatbots, should have a clear bias disclosure like LLaMA’s, but very few do.
OpenAI’s GPT-3 model card does not disclose these bias scores. To find out how GPT-3 is biased along the same nine dimensions, you would have to dig into the LLaMA academic paper, where it presented a side by side comparison:
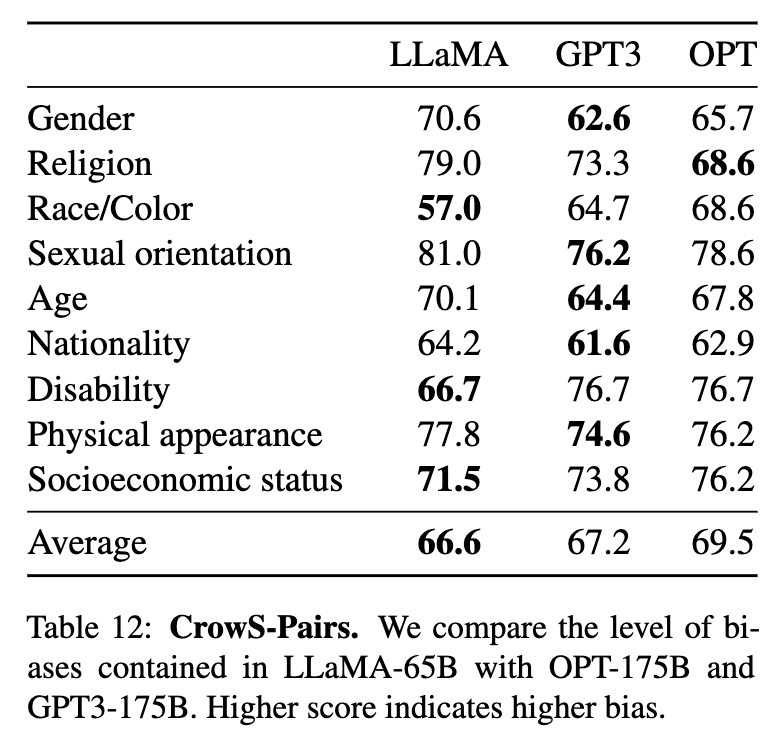
The Meta AI team, of course, did this at least in part to make LLaMA look good, though its average bias score is less than one point lower than GPT-3’s. In fact, GPT-3 actually scores better than LLaMA in five of the nine categories, so OpenAI has nothing to be ashamed of.
This begs the question: how come no other LLMs – from GPT-3.5 and LaMDA (Google), to ERNIE (Baidu) and Chinchilla (DeepMind, so also Google) – lay out their bias scores as clearly as Meta’s LLaMA? What is there to hide?
If these other models also made similar disclosures, then the AI research community, as well as the general public, would have a starting point to investigate and operate on good faith, rather than dragging AI into a human culture war and wasting our breath arguing if ChatGPT is “woke.”
Model Is Not Moat
Implicit in Meta’s decision to open source LLaMA is a view that the model itself is not that valuable to its business. It is a rather enlightened view and one I happen to share.
All machine learning based AI use cases – LLMs for text generation, Stable Diffusion for image creation, prediction engines for content recommendation – are subjected to the “garbage in, garbage out” problem. If you use the most vitriolic threads on Reddit as the training data for an LLM, a chatbot built using that LLM will sound toxic and hateful, no matter how advanced that model is. If your training data only contains content written in American English, speaking to that chatbot in German won’t perform that well, let alone in Japanese.
That’s why the results that a chatbot like ChatGPT generates – the “answers” you get when you chat with it – is technically called “inferences.” They are outputs inferred from the data that it was used during training.
The business value lies in the cleanliness and quality of the training data, and how closely do those data match with the task that the AI application is supposed to solve. If you are building a self-driving system, having the clearest and most updated driving and road condition data is the most important thing. If you are building a health insurance chatbot, like I have foolishly tried to do before, having accurate insurance data and medical procedure pricing is the most important thing. Other unrelated data are just noise and can have adverse effects on the model’s performance.
This is not to say that the models are not valuable. They are. Being able to build models with hundreds of billions of parameters that generate more accurate inferences faster, all the while consuming less computation when deployed is no easy feat. But this “model value” will become more of a “tax”, less of a product differentiator over time. This progression is already unfolding. The speed in which Salesforce has launched ChatGPT-like functions in Slack and its vast suite of sales and marketing SaaS products, so soon after Microsoft has done the same in its own vaste suite of enterprise applications, is a case in point. Smaller SaaS companies like ZoomInfo and Notion are doing the same thing. They are all using the same set of OpenAI models underneath the hood.
The model is not the moat. An advanced model can transform quality data into business value. But the reverse is not true: without quality data, a model is useless no matter how advanced it is – like a brand new highway without cars.
On the other hand, by keeping models as secrets in a black box, it could breed confusion and distrust. This sense of secrecy may create intrigue and attract more customers in the short term, but over time more users will want to know the “how” and “why” behind the model, which if not answered openly and transparently may decrease usage, which may lead to less quality user data as feedback and ultimately hurts the business. This problem is less of an issue with enterprise software companies like Salesforce (B2B companies don’t get dragged to Congress to testify). But for social media companies, like Meta, being open and transparent with its AI models is both good for building trust and good for business. I have shared similar views of open sourcing Twitter’s algorithm and open sourcing TikTok’s internal access system, along the same vein.
In tech, where data is plentiful but trust is scarce, open sourcing your AI models and algorithms is a rare scenario where you can have your cake and eat it too. Meta seems to have figured that out and is going above and beyond its competitors with the way it released and open sourced LLaMA.
It is an example that others should follow. It is an example that OpenAI should have set, given its original mission and commitment to open source. With harsh critiques coming from the likes of Elon Musk and others, who originally co-founded the organization, OpenAI, Google, and others may be forced to follow Meta’s example eventually, before trust begins to erode.
OpenAI was created as an open source (which is why I named it “Open” AI), non-profit company to serve as a counterweight to Google, but now it has become a closed source, maximum-profit company effectively controlled by Microsoft.
— Elon Musk (@elonmusk) February 17, 2023
Not what I intended at all.
Meta 真的变成了一家值得信赖的 AI 公司了吗?
在所有参与火热的 AIGC 竞争的科技大厂中,我认为最值得信赖的公司今后可能会是 Meta。没错,就是扎克伯格的 Meta。
我之所以这么说,是因为其最近发布的大型语言模型 LLaMA(Large Language Model Meta AI)是开源的,与其他类似 LLM 相比,它把模型在性别、宗教、种族和其他六个方面的偏见,清晰披露了每个纬度在业界里标准的偏见评分。
长期关注 《互联》的读者们知道,我对开源的价值有很深的了解和信心,既认为它是一种优越的技术开发模式,也认为它是构建用户、产品和监管者之间信任的最佳方法。换句话说:阳光是最好的消毒剂。(详见我之前关于这个话题的大量文章。)
令人惊讶(或不惊讶)的是,在美国公众心里最缺乏信任的 Meta,正借助开源的力量来增强其 AI 的可信度。与此同时,Meta 的同行们却将他们的 AI 模型视为自己的 “秘密武器”。这两种不同的打发的长远影响非常值得关注,因为各种生成AI的应用只会变得更加普及和大众化。

模型卡(Model Card)
LLaMA 最突出之处是它的 “模型卡”。
模型卡是机器学习研究领域中的一种新标准,每个新训练出来的模型都应该公开分享一组性能基准、预期用例以及一套多维度的关于不同文化和人文的偏见指标。模型卡通常是这些信息的总结,类似于一个开源项目的README或文档。
这个标准首次出现在2018年的一篇学术论文中,题为《Model Cards for Model Reporting》,作者是曾在谷歌工作、现在在Hugging Face(一家专注于机器学习开发的平台)工作的AI伦理研究员Margaret Mitchell。从那时起,新公布的机器学习模型开始在发布过程中也写一篇模型卡,这种做法越来越普遍。但是每篇模型卡的质量参差不齐。
LLaMA的模型卡是我迄今为止看到的最清晰、最透明的一个。它列出了模型中四个不同版本的参数大小(7B、13B、33B和65B参数)、有一个部分专注于 “预期用途” ,以及关于训练该模型所用的数据类型的详细信息。最重要的是,它披露了一组关于性别、宗教、种族/肤色、性取向、年龄、国籍、外貌和社会经济地位的偏见度评分,分数越低,模型的偏见行 “越低”。以下是LLaMA的评分:
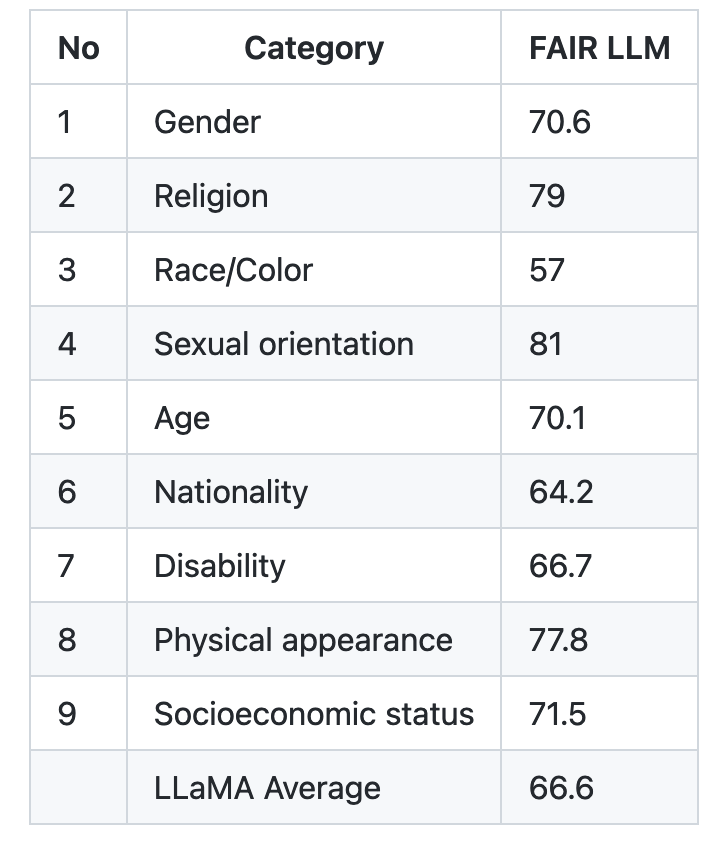
需要澄清的是 我们看LLaMA 模型卡中的偏见评分的目的,并不是要评判这个模型对谁有偏见 – 不能简单地通过这些分数来说 LLaMA 在某种程度上没有严重的 “种族歧视”,却有更多 “年龄歧视”。更重要的一点是,每个机器学习模型,尤其是驱动着众多聊天机器人的LLM,都应该像LLaMA一样有明确的偏见评分的披露,但很少有。
OpenAI的GPT-3模型卡里没有披露这些偏见评分。要了解GPT-3在同样九个维度上的偏见评分,还要看LLaMA的论文:
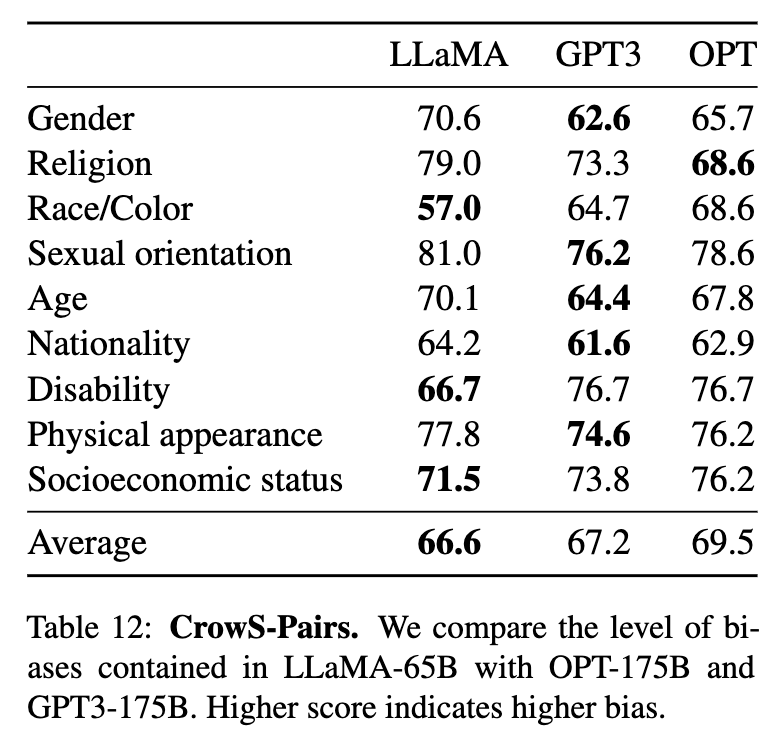
当然,Meta AI 团队之所以把LLaMA和GPT-3的偏见评分都公布在自己的论文里,或多或少是想给LLaMA打分,尽管其平均的偏见评分也就比GPT-3低一点而已。实际上,在九个偏见类别中,GPT-3在五个类别上的得分比LLaMA更低,所以OpenAI无需为此感到羞愧。
从而引发了一个更大的问题:为什么其他的LLM,例如GPT-3.5、LaMDA(Google的)、ERNIE(百度的)和Chinchilla(DeepMind的,也就是Google的)都没有像Meta的LLaMA那样大方清楚地公开它们的偏见评分?都有什么要隐藏的呢?
如果这些其他的模型也提供类似的披露,那么做AI研究的学术圈以及广大公众用户就可以有一个共同起点来在基于诚信的基础上研究这些AI有没有偏见,也不用费口舌把AI拖入人与人之间的“文化战”,浪费时间争论ChatGPT是否“woke”。
模型不是护城河
Meta决定开源LLaMA背后更深渊的商业含义是,模型本身对于其业务来说并非那么有价值。这是一个相当开明的观点,也是我恰好赞同的观点。
所有基于机器学习的AI用例 —— 用LLM生成文字,用Stable Diffusion做图片创造,用预测引擎推荐内容 —— 都会被 ”garbage in,garbage out” 所影响。如果训练模型时用的是 Reddit 上最恶毒的帖子作为训练数据,那么用该LLM做出来的聊天机器人就会充满恶意和仇恨,无论模型本身有多先进。如果训练数据只包含美国英语写出的文字内容,那么用德语与该聊天机器人交谈的效果就不会太好,更不用说用日语了。
这就是为什么像ChatGPT这样的聊天机器人生成的结果 — 也就是在与它聊天时获得的“答案” — 在技术上严格是被称为“推断”(inference)。它们是从训练过程中使用的数据推断出的“答案”。
商业价值的体现在于训练数据本身的干净度和质量,以及这些数据与用例要解决的任务之间的匹配有多近。如果你正在构建一个自动驾驶系统,拥有最清晰、最新的驾驶和路况数据是最重要的。如果你像我一样也曾经天真地尝试过去搭建一个与健康保险有关的聊天机器人,拥有准确的保险数据和各种治疗方法的定价是最重要的。其他无关的数据只是噪音,可能对模型的性能还会产生负面影响。
我并不是说模型没有价值。它们是有价值的。能够搭建一套含有数千亿参数的模型,以更快的速度生成更准确的“推断”,同时在部署时消耗更少的计算资源都并非易事。但随着时间的推移,这类 “模型价值” 会变成一种 “税”,而不再是产品差异化的要素。这种演变已经在发生。微软在自己的企业软件中推出ChatGPT功能的不久后,Salesforce在Slack及其自己的销售和营销SaaS产品中就推出了类似功能。像ZoomInfo和Notion这些更小一点的SaaS公司也在做同样的事情。这些都是“模型不是护城河”的例子,因为在底层他们都在使用同样的OpenAI模型。
一个先进的模型可以把高质量的数据转化商业价值。但方向反过来却不成立:没有高质量的数据,无论模型多么先进,都是无用的 — 就像一条没有汽车的崭新高速公路。
另一方面,把模型当作“黑盒子” 神秘的保护,只会导致困惑和不信任。这种神秘感短期也许能制造出些悬念,吸引用户,但随着时间的推移,越来越多的用户会想了解模型背后的内涵和算法,如果不能公开透明地回答这些问题,那会导致使用量减少,导致用户反馈的数据质量下降,最终损害产品和业务。这对于像Salesforce这样的企业软件大厂来说到问题不大(B2B公司不会被拖到国会作证)。但对于像Meta这样的社交媒体公司来说,公开透明地展示其AI模型既有利于建立信任,也有利于业务发展。我曾就开源Twitter的算法和开源TikTok的内部访问系统分享过类似的观点。
科技界所面临的是数据丰富但信任稀缺,开源自己的AI模型和算法是一个罕见的一箭双雕的打发。Meta似乎意识到了这一点,在发布和开源LLaMA的方式上超越了竞争对手。
这是其他大厂应该效仿的。这是OpenAI本应树立的榜样,鉴于其初心和对开源的承诺。随着马斯克等人的严厉批评(他们都是最初组织OpenAI的合伙人),OpenAI、谷歌以及其他公司也许最终不得不效仿Meta的做法,否则与公众的信任可能会逐渐消失。