
I’ve written many posts on the global public cloud ecosystem lately, from in-depth comparisons of the big ones: AWS, Alibaba Cloud, Azure, Google Cloud Platform, to a few of the less prominent but still very competitive ones: IBM, Oracle, Tencent.
All of these clouds are spawned out of already-large tech companies, many of whom have built a massive technical infrastructure to support their original businesses, then turn those resources into services to rent out in the form of cloud. As I have discussed before, Google has always had the most global and technologically advanced infrastructure among its peers, because it needed to support a dominant search engine and many other services and apps that must be “always on” around the world. The one company that most closely resembles the same technical requirements and demands is Facebook.
Yet, Facebook does not have a cloud business, despite outside speculation and even some Wall Street analysts openly demanding it.
Why?
[NOTE: if you are interested in more cloud-related analysis on Interconnected, please checkout the newsletter's Cloud Industry category.]
Just Not Interested
It’s definitely not because Facebook doesn’t have the technology. In fact, Facebook has been incredibly successful in inventing new technologies in multiple layers of the technical stack to support its huge user base and new features, which are increasingly AI-intensive. There would definitely be companies interested in paying to use those technologies for their own use cases. Instead of monetizing them, Facebook has chosen to open source them, allowing any one to use and modify them for free.
A few fairly well-known examples:
- Cassandra, RocksDB (databases)
- GraphQL (app server layer)
- React (front end)
- PyTorch (deep learning AI)
Its preference for open source, as opposed to direct monetization, reached into the very heart of any cloud platform -- data centers. In 2011, when Facebook put its brand new data center in Prineville, Oregon online, it also open sourced that data center’s entire design, from custom-built servers to a cooling system that was fueled by cold air from the outside, as opposed to electric-powered water chillers in traditional data center design.

The open sourcing of this design led to Facebook initiating the Open Compute Project, a foundation to shepherd and evolve these designs further with other tech companies. Out of the large public cloud providers, Alibaba, Google, IBM, Microsoft, and Tencent are all members of the Open Compute Project. Amazon, the market leader, is not. It’s quite possible that these members of the Open Compute Project are all leveraging the designs that Facebook initially came up with to build their new data centers today. And Facebook doesn’t seem to mind one bit.
Clearly, Facebook didn’t care much for the enterprise IT business back then and didn’t think innovative data centers were even a competitive advantage worth protecting (unlike Google). Its infrastructure is built for the single purpose of growing its user base like crazy and selling ads to them.
Is it too late to change its mind?
Too Crowded or Room for More
The global public cloud computing spending was $229 billion in 2019 and will grow to $500 billion in 2023, according to IDC. The North America market is projected to be more than half of that growth, while Western Europe is second with close to 20%.
There’s plenty of growth left to go. But no one is standing still.
The way I see it, there is room for more -- one more -- if the new entrant has enough differentiating technologies and a track record of innovation. And Facebook could be that one, given its history of innovation on all levels of the stack. Most players in the industry are still in what I call “land grabbing mode”, selling the cloud basics of compute and storage resources wired by quality networking, before moving up the value chain with higher-end, differentiating services, like machine learning APIs and large-scale distributed databases.
Facebook currently has 15 data centers around the world, 11 of which are in the United States, with three in Europe and one in Asia. The U.S. is the biggest and most lucrative cloud market at the moment, so if Facebook does decide to rent out a portion of its capacity as a cloud service, it already has strong coverage to support it. If it can turn its Al capabilities into easily consumable APIs, trained already on its billions of users and an ungodly number of pictures, videos, and texts, a hypothetical “Facebook cloud” could offer very attractive, differentiating services beyond the basics of compute, storage, and network.
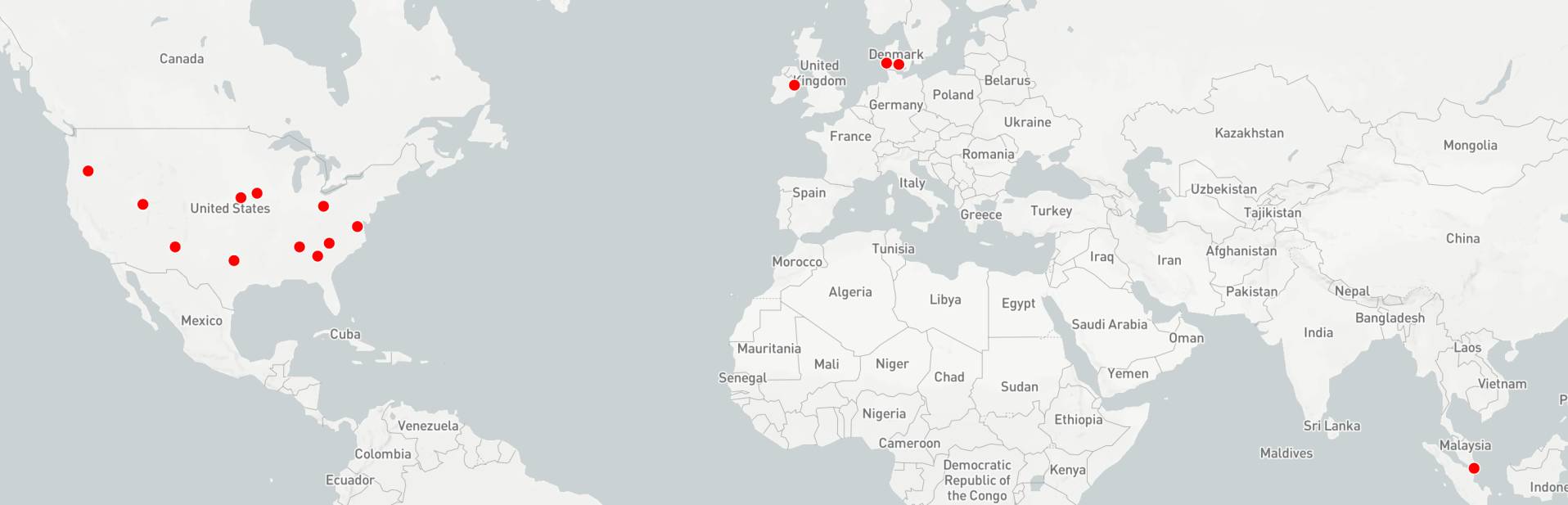
The tougher part is perhaps not technical, but human. Facebook will have to build out an enterprise sales and support team that is culturally and operationally very different from running an ad-supported social network. Google, also a primarily ad-supported company, suffered from this “identity crisis” and is still trying to catch up to AWS and Azure, despite offering what many believe is a superior technical product.
Technology never just sells itself, no matter how good it is.
Trust Deficit
Even if Facebook solves the technical and personnel challenges and has marshaled both the will and financial resources (which it has) to go into the cloud business, its biggest hurdle is trust, given its problematic record on data privacy.
During the early days of the public cloud, mid to late-2000s give or take, the biggest resistance from large companies to the cloud was lack of privacy and control. That’s why most cloud users were small startups or greenfield projects that did not have high privacy requirements, and did not need any migration of data. (Large enterprise CIOs are generally risk averse and hate migration of any sort.) That concern has subsided somewhat, as shown by the growing usage of cloud services generally. But it’s still there, which is giving rise to the “private cloud” or “hybrid cloud”.
That’s the rationale behind AWS’s Outposts offering and GCP’s Anthos. Both AWS and GCP (and others) are willing to provide the software and hardware to build a completely separate cloud (“private cloud”) inside a large enterprise’s own facility (“on-premises”) with network connectivity to their existing public cloud (“hybrid cloud”). All this extra work is intended to alleviate large companies of privacy, compliance, security, and regulatory concerns, while giving them maximum control. These concerns are especially acute for enterprises in tightly-regulated industries like financial services, healthcare, energy, and telecom. But they are deep-pocketed customers, so all the extra work is worth it.
Engaging in these types of customers must begin from a baseline of trust. And if you have a deficit of trust, either real or perceived, the road ahead is rough. Google is already suffering from its own trust deficit with the healthcare industry, caused by its questionable record on data privacy. AWS has steered clear of most industries’ concerns, except for other retail and e-commerce companies, though that’s due more to market competitive dynamics than data privacy. Alibaba Cloud’s trust deficit is rooted in trade wars, nationalism, and a strong suspicion of the government of its home country that goes far beyond technology or loosely-worded privacy policies. Microsoft’s Azure is the only major player that does not have a trust deficit, which is perhaps a main driver for Azure’s impressive growth, despite what I believe to be inferior technology and architecture.
Facebook’s troubling history with data privacy is well-documented at this point. Can it overcome it eventually and build a meaningful cloud business?
Never say never. It wasn’t that long ago, maybe five years at most, when Facebook was a company that could do no wrong. And now it’s a company that could do no right. In reality, the truth is always somewhere in between the extremes.
As COVID-19’s impact in the U.S. and around the world intensifies, normal freedoms of activities and movements that we all take for granted are being restricted everywhere. A second-order effect of these restrictions may be diminishing concern for digital privacy, when our personal physical privacy is limited to combat spread of the coronavirus -- an opportunity for Facebook to resuscitate its reputation.
It’s possible that Facebook has already decided that it has missed the cloud gravy train and so be it. Instead, it has moved on to the next generation of distributed computing technology -- the blockchain -- which would explain the significant amount of capital, both financial and political, that Facebook as a company and Mark Zuckerburg as an individual have put into the Libra project.
In classic Facebook fashion, when it announced Libra in June 2019 the initial code base was open sourced, much like the data center designs that seeded the Open Compute Project. Unlike the Open Compute Project, the Libra Association has since faced widespread media skepticism, opposition from multiple central banks and regulators, intense questioning by the U.S. Congress, and many initial members pulling out.
Launching a cloud would be a lot easier, with few regulatory hurdles and a straightforward business case. But maybe Facebook just wasn’t and still isn’t interested. It has a lot more to prove and show to the world, it seems, than just generating another revenue stream.
New posts will be delivered to your inbox weekly. Follow and interact with me on: Twitter, LinkedIn.
为什么Facebook不做云的生意?
我最近写了很多关于全球公有云市场的文章,从深入比较AWS、阿里云、Azure、GCP,到分析一些不太突出但仍然极具竞争力的平台:IBM、Oracle、腾讯。
这些云都是已经成气候的科技巨头的一个分支,这些公司已经建立了庞大的技术基础设施来支持他们原来的业务,然后再将这些资源转变成云服务,出租出去。正如我之前所分析过的,谷歌一直拥有最全球化和技术最先进的基础设施,因为它需要支持一个庞大的搜索引擎和许多其他服务和应用程序,而它们都必须在全球 “always on”。从这个角度看,Facebook是最接近谷歌的公司。
然而,尽管有外界猜测,甚至有一些华尔街分析师公开要求,Facebook并没有云业务。
为什么呢?
【注:如果您对与云有关的分析感兴趣,请看《互联》的云行业文章分类。】
就是没兴趣
这肯定不是因为Facebook技术不行。Facebook在技术堆栈的多个层面上创造了许多新技术,来支持其庞大的用户群和新功能,很多都需要人工智能。肯定会有公司愿意花钱使用Facebook先进的基础技术。但Facebook并没有把它们当摇钱树,而是都开源了,免费给大家使用和改造。
一些比较有名的例子:
- Cassandra,RocksDB(数据库)
- GraphQL(服务器层)
- React(前端)
- PyTorch(深度学习)
Facebook对开源的偏好直接深入到了所有云计算平台的核心:数据中心。2011年,当Facebook将其在Prineville,Oregon州新造的数据中心启动时,同时也开源了该数据中心的整个设计蓝图,从定制服务器到由户外冷空气驱动的冷却系统,改造了传统数据中心设计中的电动冷水机组。

开源数据中心的设计即是Facebook启动一个新的非盈利基金会Open Compute Project的前奏。通过这个组织,Facebook想让数据中心设计继续进步,并与其他科技公司合作。在所有公有云大厂中,阿里巴巴、谷歌、IBM、微软和腾讯都是Open Compute Project成员。市场领头羊,亚马逊,却不是。这些Open Compute Project的成员应该多多少少都在利用Facebook最初的设计来构建他们今天的新数据中心。Facebook也并不介意。
Facebook当时对企业IT业务根本没兴趣,也不认为有创新的数据中心是一个值得保护的竞争优势(不像Google)。它的所有基础设施都为一个目的服务,疯狂地增长用户群,给他们卖广告。
现在改变主意还来得及吗?
太拥挤还是空间还很大
据行业分析所IDC的估算显示,2019年全球公有云计算支出为2290亿美元,2023年将增至5000亿美元。北美市场预计将是整个增长的一半,而西欧会拥有整个市场的将近20%,位居第二。
总之还有很多增长空间,但是每个厂商都在赛道上奔波。
在我看来,顶多还有给一个新玩家的空间,而且它需要有足够的差异化技术和屡屡创新的能力。Facebook就是这样一家公司。行业中的大多数厂家仍处于我所称的“争地盘模式”。在主攻卖高端服务之前(比如机器学习API和大规模分布式数据库),他们销售的重点还是公有云的基础服务:优质网络连接的计算和存储资源。
Facebook目前在全球有15个数据中心,其中11个在美国,3个在欧洲,1个在亚洲。美国是目前最大、利润最多的云计算市场,因此如果Facebook真的决定将一部分资源变成云服务卖出去,它已经拥有足够的覆盖范围来支撑这个新业务。如果它能将自己内部的机器学习模型变成外界可用的API(都是已经经过数十亿用户和他们所有的图片、视频和文字训练过的模型),那么这个“Facebook云”可以提供非常有吸引力、与其他竞争对手有差异的公有云平台。
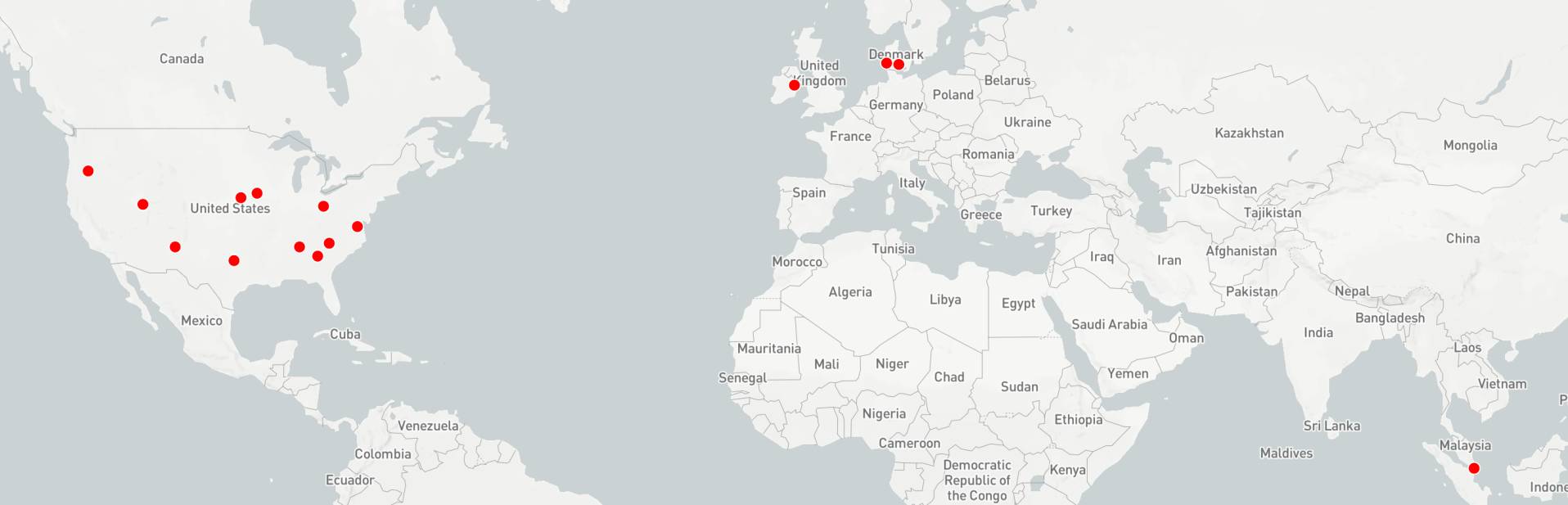
更难做到的其实未必是技术,而是人。Facebook必须建立一个企业销售和客户支持团队,这个团队在文化和运营上与一个卖广告的社交网站会完全不同。谷歌同样是一家主要靠广告盈利的公司,它已经尝到了文化冲突的苦头。尽管许多行家都认为GCP的产品和技术优于AWS和Azure,因为没有企业销售和支持的根基,它的市场份额仍然落后。
不管技术有多好,它都不会自己卖自己。
信任缺失
即使Facebook解决了技术和人员方面的挑战,并下定决心杀入云这个市场,它面对的最大的问题其实是整个公司在用户数据隐私方面的种种缺陷,而导致的信任缺失。
在公有云的早期,大约2000年代中后期,大公司对云的最大阻力是缺乏数据隐私和管控。这就是为什么大多数云用户一开始都是小型初创企业或新项目,它们没有很高的隐私要求,也不需要任何数据迁移。(大企业的首席信息官CIO通常都怕风险,最讨厌数据迁移这种事。)现在这种担忧已经有所缓解,所以云服务开始普及,但它仍然存在。这就是为什么行业里开始有“私有云”和“混合云”。
AWS Outposts和GCP Anthos这两款产品都是为了满足市场中的这种需求。AWS和GCP(以及其他云厂商)都愿意提供软件和硬件,在大型企业自己的设施内(“on-premises”)构建一个完全独立的云(“私有云”),并可以与自己的公有云链接在一起(“混合云”)。所有这些额外的服务都是为了减轻大公司对隐私、法规、安全和监管方面的担忧,同时给予它们最大限度的管控能力。对于金融服务、医疗、能源和电信等监管严格的行业来说,减轻这些担忧尤其重要。这些额外的工作也都是值得的,因为他们都是财大气粗的客户。
要想赢得这种客户的生意必须要有信任的基础。如果厂商不可信,不管是真正的还是感知的,就很难继续往前走。因为在数据隐私方面做的不好,谷歌已经在医疗行业里吃了亏。除了其他零售和电商公司以外,AWS并没有被很多行业怀疑,电商不用AWS也并非是因为数据隐私问题,而更是由于市场竞争的关系。
阿里云在市场上的信任缺失源于贸易战、民族主义,以及对其祖国政府的强烈怀疑,远远超出了对技术或数据隐私方面的不信任。微软的Azure是唯一一家在信任方面没什么问题的公有云大厂,也是Azure能快速增长的因素之一,尽管我认为它的技术和架构和对手比都有很多不足。
Facebook在数据隐私方面令人不安的历史已经众所周知了。它能最终克服这个问题,打造一个有规模的云业务吗?
永不言败。就在不久前,最多5年前,Facebook还是一个科技行业的佼佼者,现在却变成了人见人骂的活靶子。然而现实的真相总是介于两个极端之间。
随着新冠疫情在美国和世界各地的影响加剧,大家正常的生活和行为都在各个方面受到限制。这些限制的二级效应很可能是人们对网上隐私这个问题的关注降低,因为我们线下的个人生活都已经为了对抗新冠的传播而被限制——这是也许是Facebook恢复声誉的好机会。
也有可能的是,Facebook已经知道上云的这艘大船已经晚了,也放弃了。它已经把目光转移到下一代分布式计算技术:区块链。这也是为什么Facebook作为一家公司和扎克伯格作为个人都愿意在Libra项目上投入大量的财务和政治资本。
当Libra在2019年6月发布时,Facebook按照自己的老习惯,也把项目的代码都开源了,就像当时建立Open Compute Project时开源提供自己的数据中心设计。当然,与Open Compute Project截然不同的是,Libra协会一公布就遭到媒体的广泛质疑、多家央行和监管机构的反对、美国国会的质问,以及许多最初说好参与的成员的退出。
相对而言,做公有云业务要容易得多,没有什么监管障碍,而且是一门简单明了的生意。但也许Facebook至今还是不感兴趣。它似乎要向世界证明和展示的,不仅仅是多创造个收入来源,多赚点钱。
如果您喜欢所读的内容,请用email订阅加入“互联”。每周两次,新的文章将会直接送达您的邮箱。请在Twitter、LinkedIn上给个follow,与我交流互动!