
Nearly two years after ChatGPT, AI coding assistant is perhaps the only product that has found the ever-elusive PMF (product market fit). Almost every programmer is using some form of AI-powered copilot-type product, even when their employers don’t encourage it – does not get more PMF than that!
The two undisputed leaders in this space are GitLab and GitHub. GitHub happens to be my most recent full-time employer, before taking the plunge to strike out on my own. GitLab happens to be one of the longest serving members in my portfolio, something I discussed briefly in my Q1 2024 letter. Needless to say, I think about this space a lot.
A few recent news items between the competition of these two AI coding giants caught my attention and further cemented a suspicion I’ve had for some time – being model agnostic is an advantage and there is an AI model divide forming in the coding landscape.
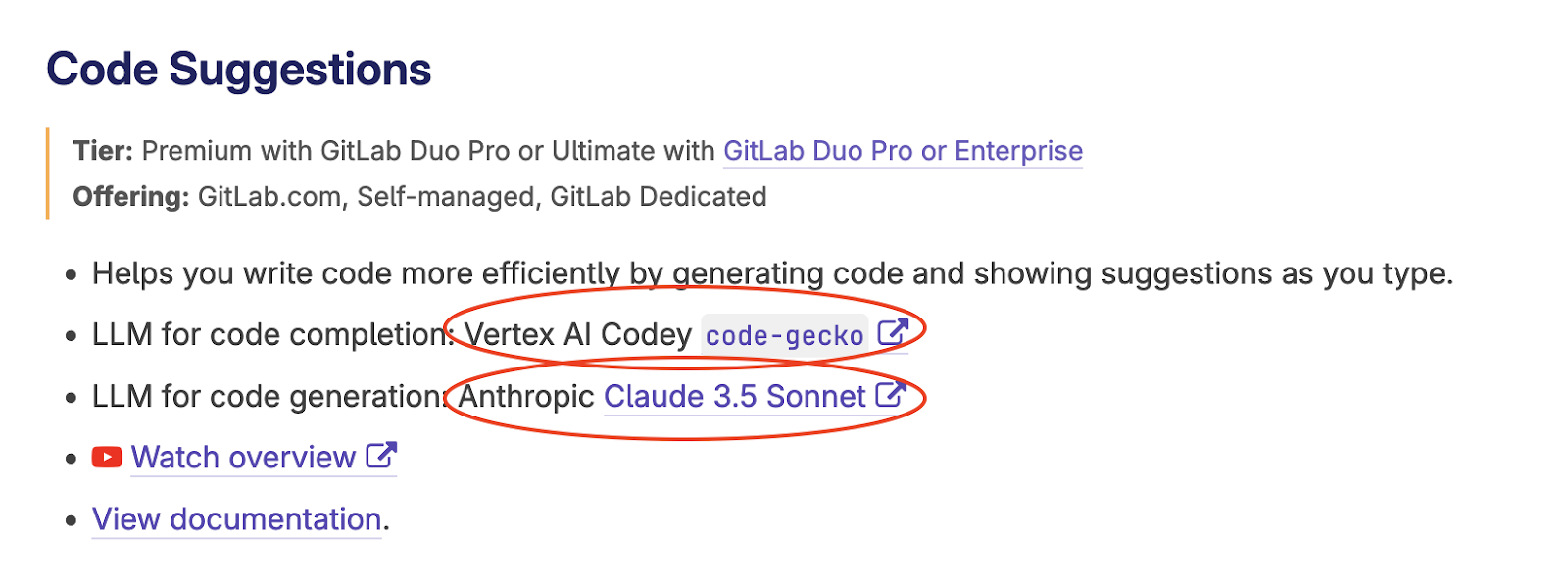
First, in early September, GitLab revealed during its earnings call that GitLab Duo, its AI coding product, has switched from Google’s Vertex to Anthropic’s Claude as the model for its code generation feature. This is a big deal because GitLab has always been perceived as tied closely to the Google Cloud ecosystem, not the least because Alphabet is its 2nd largest shareholder (owns 6% of its market cap at the time of this writing). Yet, GitLab switched to Claude, which is more closely tied to the AWS world, because Anthropic’s new model has made huge strides lately in its coding capabilities and is becoming more preferred among programmers.
Second, last week, OpenAI dropped its latest model, the o1 series, that is more capable in complex tasks that need lengthier reasoning. As part of the release, GitHub, which is of course owned by Microsoft and almost exclusively tied to the Azure ecosystem, announces a preview access to o1’s capabilities inside GitHub Copilot. (Presumably, GitLab would not be able to offer the same preview, because it is competing with GitHub head on.)
Last, and certainly not least, earlier this week, Satya Nadella, during a product release video of new Microsoft Office 365 Copilot features, called AI models “more of a commodity”. Yes, you heard that right. The CEO of the three trillion dollar giant, who has the cash to buy up every single AI model startup out there if he feels like it, just called AI models a commodity.

There is much to unpack between the models’ ever-changing capabilities, their relationships with GitLab and GitHub, and what these dynamics in the AI coding world portend for all the other AI use cases that are still searching for PMF.
GitLab, GitHub, What’s the Diff?
It’s worth going back in history real quick to explain the differences between GitLab and GitHub, before we dive deeper into the present. For people who don’t follow this space closely, the very-closely-sounding names of two very different companies can be confusing.
We must first start with “Git”, the first half of the names. Git is an open source version control system – a piece of software that helps developers keep track of different changes to a code base and merge them in the desired order (or reject the undesirable changes). Git was created in 2005 by Linus Torvald, who created Linux, the now de-facto open source operating system ubiquitous in every computer and cloud platform. Torvald created it to solve the massive coordination task of version controlling and change merging of the development of Linux, a growing open source project at the time. (He also admitted later that he created Git, so he was not seen as a “one hit wonder” – every genius has a chip on his shoulder.)
While there were other version control systems before Git, like Sourceforge, Subversion, Perforce, and (now defunct) Google Code, Git was engineered to specifically solve the distributed nature of open source software development. It’s not terribly hard to version control inside a single team or company building a proprietary software, which was how most technology was built up to the 2000s. But you can imagine things getting hairy quickly if the software is out there on the Internet, publicly accessible and open for any developer to download, use, and make changes to (aka open source). Tracking all that would be a nightmare without a piece of (preferably also open source) software designed for this problem.
Still, Git was not the only solution. Mercurial, another open source version control system, was created at around the same time to solve a similar problem. It is still alive today with prominent users, like Meta and major universities. (I first used Mercurial when studying Computer Science at Stanford.) But Git is by far the most popular now, if not the de-facto standard for most programmers around the world.
Why did Git win is still a topic of much debate and intrigue today. Having been created by the most famous open source creator (and provocateur) of all time, Linus Torvald, definitely helped. The rise of open source development, and the unique needs this development model posed, created rising demand. But no matter how you slice and dice this debate, GitHub had a lot to do with it.
GitHub, the company, was founded in 2008. It started out as simply a web-hosted version of Git, so using Git became less of a “pain in the ass” for developers. It was a Hub for Git projects – or GitHub. One open source community at the time that loved GitHub was the Ruby community. As Ruby became popular and en vogue during that time, so did GitHub.
GitHub today is still in many ways serving its original mission – a hosted Git platform that is not a pain in the ass and developer friendly. The confluence of multiple waves rising – open source, Ruby, Git – resulted in GitHub hosting more than 90% of the world’s open source software, including Git itself. (If you haven’t had enough of this story yet, this blog post on why GitHub won, written by one of its co-founders, Scott Chacon, is a great read.)
The battle for who would dominate the Git ecosystem should have ended here, except for one ironic wrinkle to how GitHub works. While GitHub hosts almost all the open source projects, GitHub itself is not open source. Some people in the open source community found this problematic and decided to make an open source version of GitHub, and called it GitLab.
GitLab was created in 2011, three years after GitHub. But it was just another open source project and didn’t become a company until 2014, when GitLab Inc. was registered. Since its early days, GitLab’s identity was very much tied to being a real open source alternative to the ironically closed source GitHub, as evidenced by this 2016 blog post by Sid Sijbrandij, GitLab’s CEO. But it struggled to make money in the beginning and iterated through pretty much every business model under the sun, until it finally landed on what it calls the “buyer-based open core” model.
This business model is quite ingenious and put GitLab on a rocketship trajectory to compete with GitHub in the commercial space. In a nutshell, GitLab today is a “glue” of many different open source projects, each solving a discrete problem in the software development process – hosting source code, deploying code, testing code, securing code, etc. GitLab glues all these existing developer tool projects (many probably started on GitHub) into a coherent enough platform to sell to companies who want all these solutions, but would prefer that someone else who knows what they are doing do the gluing, rather than doing it in-house. And they would be happy to pay for it. Those companies ended up being large enterprises with limited IT expertise – a great type of buyers. This “open source glue” approach is a key reason why GitLab sports one of the best gross margins in the industry today – a whopping 91%!
Fast forward a few more years, GitHub got acquired by Microsoft in 2018. GitLab remained independent and became a public company in 2021. The two-company race for global developer dominance blazed ahead.
Model Agnostic, Model Divide
With this short history primer of Git, GitHub, and GitLab in mind, let’s now move into the generative AI age. For programmers, AI started earlier than the rest of the world, in June 2020 when GPT-3 was launched. (ChatGPT was the 3.5 version.)
I remember that launch more vividly than I did of ChatGPT, when, locked in my apartment in Silicon Valley to comply with lockdown orders of Covid-19, I tracked the launch closely, was wowed by its coding ability, and wrote about it back then. In 2020, GitHub was officially part of the Microsoft orbit, while OpenAI was quickly becoming so. GPT-3 was good enough that Microsoft had an exclusive license to use it and passed it on to GitHub to develop the first Copilot.
GitHub Copilot quietly launched in technical preview mode (meaning only for the most hardcore and friendly developer users to solicit feedback) in mid-2021. The product became generally available in June 2022 – five months before ChatGPT. Meanwhile, GitLab was caught flat-footed and off guard, something they readily admit today.
With Copilot, GitHub appears to be racing ahead again versus GitLab with its special access to OpenAI’s best models as a key advantage. But after ChatGPT launched a global AI model-building race in the US, China, Japan, Germany, France, and the Middle East, being “model agnostic” became GitLab’s edge in catching up. Instead of being tied closely to OpenAI’s progress, GitLab can pick and choose the best models on the market for its product’s needs, all the way down to the feature level. Switching cost between models is surprisingly trivial in this context. The only risk is if no one can compete with OpenAI, then you are always stuck with the second best model…at best.
So far, this model agnostic nature has played in GitLab’s favor. In GitLab Duo, it uses one model for code completion (Google’s Gemini via its Vertex API), but another for code generation (Anthropic’s Claude) – picking the best model for the task. You can find this dual-model setup throughout GitLab Duo’s documentation across all its features.
Given how obvious an advantage it is to be model agnostic and let the user choose which model is best, GitHub quickly responded with its own flavor called GitHub Models. However, one wrinkle is what is offered is not all models, just models that don’t compete with or aren’t a real threat to the Microsoft ecosystem.
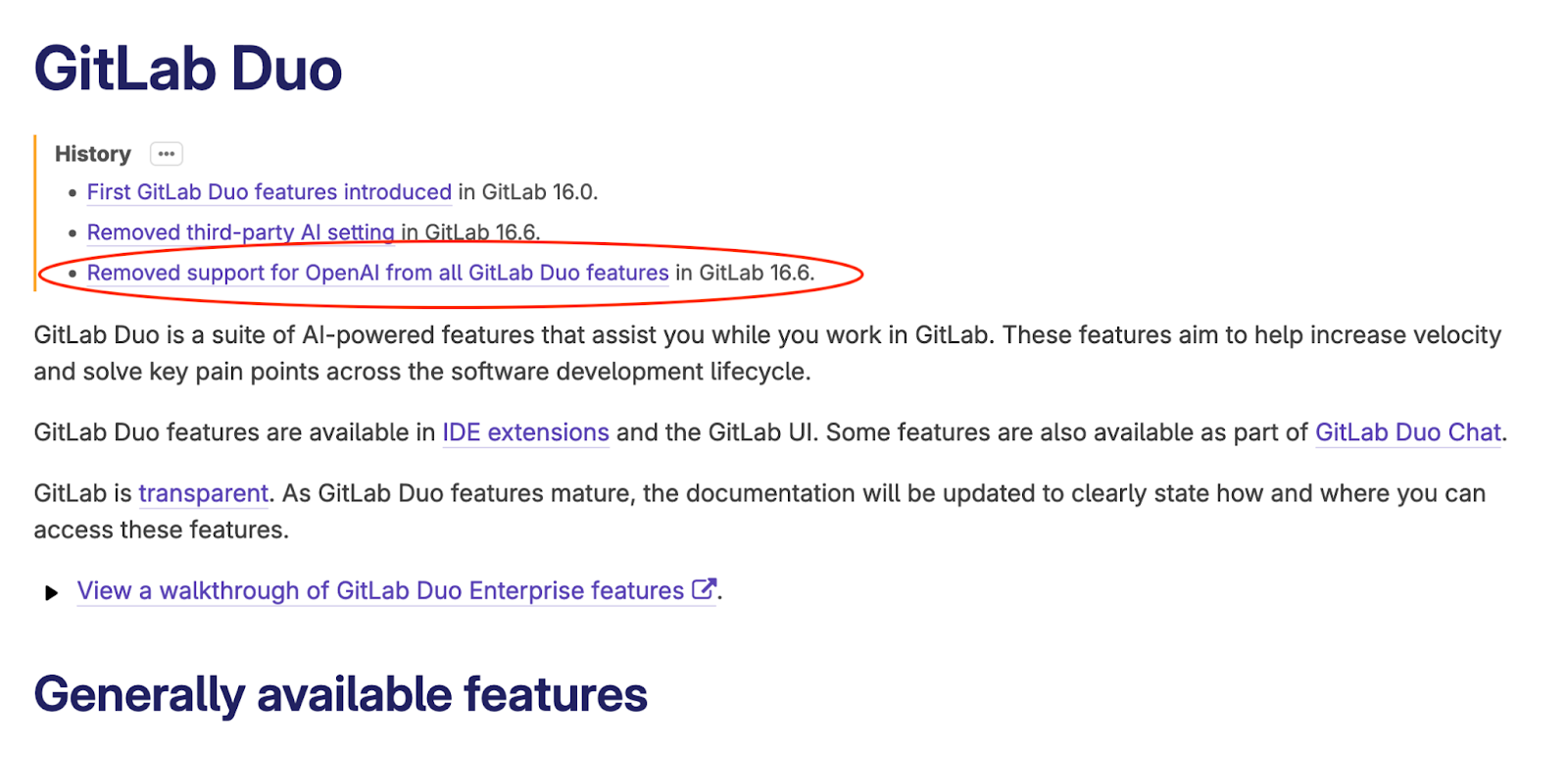
Before you complain about GitHub’s “anti-competitive” behavior, GitLab is actually doing the same thing to OpenAI! If you dig into the history of its documentation, you will find that GitLab removed support for OpenAI in its 16.6 release, presumably to either not give OpenAI models more revenue and feedback for improvement, or because OpenAI was not as supportive to GitLab given its special relationship with GitHub.
What we have on our hands is an AI model divide along a competitive fault line between the cloud giants. Why the divide? Well, models may be a commodity, but cloud ecosystem lock-in is very valuable. The best model, even if it is only the “best” for six months, may be enough to lure additional customers to eventually be locked-in to the rest of the cloud underneath the models.
So if you are a GitHub user, you are limited to models from OpenAI, Microsoft, Meta, Cohere, AI21, and Mistral (see GitHub Marketplace). If you are a GitLab customer, you are limited to models from Google and Anthropic (for AWS), though presumably, you can hook up any model you want to your instance, since GitLab is, after all, more open source than GitHub, thus more customizable.
But what if you use neither?
UI Model Fit
Luckily for developers, there are a handful of well-funded unicorns ready to break down this AI model divide – Cursor, Codeium, Sourcegraph, Magic, Cognition, to name a few. The PMF that GitHub Copilot found in AI coding assistant has triggered an obvious rush in VC investments into this category.
Here’s a useful mapping of the startup AI coding landscape courtesy of Greylock. Since it is a startup landscape, it does not include either GitLab or GitHub, because they are the 800-pound gorillas.

If you use Cursor, you can already toggle between the GPT models and Claude, going back and forth across the divide, along with its own small model that is faster and cheaper but less capable, even though OpenAI is an investor in Cursor. Codeium has articulated a thoughtful, model agnostic strategy that boils down why different models ought to be used to fit different developer experiences. For example, autocomplete is a feature that needs to be fast, so a smaller, faster model is appropriate. Chat as a feature needs to be more powerful but less latency sensitive, so deploying a SOTA (state of the art) large model makes more sense.
In the same video where Satya called models “more of a commodity”, he used another phrase to capture what a “copilot” means to him: the UI for AI. Implicit in this observation is that the UI layer is where the meaningful differentiation lies and where the value is captured, not the model layer.
Simplistically speaking, GitLab, GitHub, Cursor, Codeium are all UIs for AI for programmers. The switching cost between models is evidently low. Figuring out which element of the developer UI fits best with which type of model, so the developer finds switching to another UI too costly is the magic formula every AI coding product is searching for. You can naturally extend this insight to other product domains working to inject AI, like call centers and CRMs.
If PMF is the canonical standard for all tech products, then UMF (UI Model Fit) may be the standard for native AI products. The AI model divide, manifested by the competitive history between GitLab and GitHub, may be the current state of play. But to find true UMF, this model divide will naturally have to erode in due course.
May the AI coder with the best UMF win!