
Hype or not, GPT-3, OpenAI’s newest natural language AI model, has been percolating in the back of my mind ever since it was announced two months ago. This post will be some open musing of what I think its implications are in the intersection of tech, business, and geopolitics.
Not to get too philosophical, but I see GPT-3 as a beautiful abstraction of the relationship and tradeoffs between time and money. (Don’t worry, this isn’t the machine talking. This is still written by me, the human author, not GPT-3.)
GPT-3 in a Nutshell
To quickly summarize what is GPT-3 in plain language: it’s the 3rd generation of OpenAI’s natural language processing model, the previous generation being GPT-2, released in early 2019. GPT-3 has 175 billion parameters compared to GPT-2’s 1.5 billion parameters. In the world of Deep Learning AI, if a model has more parameters, it’s (literally) bigger, more complex, and usually produces better results. In this case, GPT-3 is more than 100-times bigger than GPT-2. GPT-3 is also trained on a much larger dataset -- almost a trillion words from the Common Crawl dataset, which crawls the entire Internet and makes the data publicly available for research. Again, in Deep Learning AI, more training data usually produces a better model, thus better results from that model. Presumably, there will be GPT-4, 5, 6, etc. that will be more powerful than GPT-3.
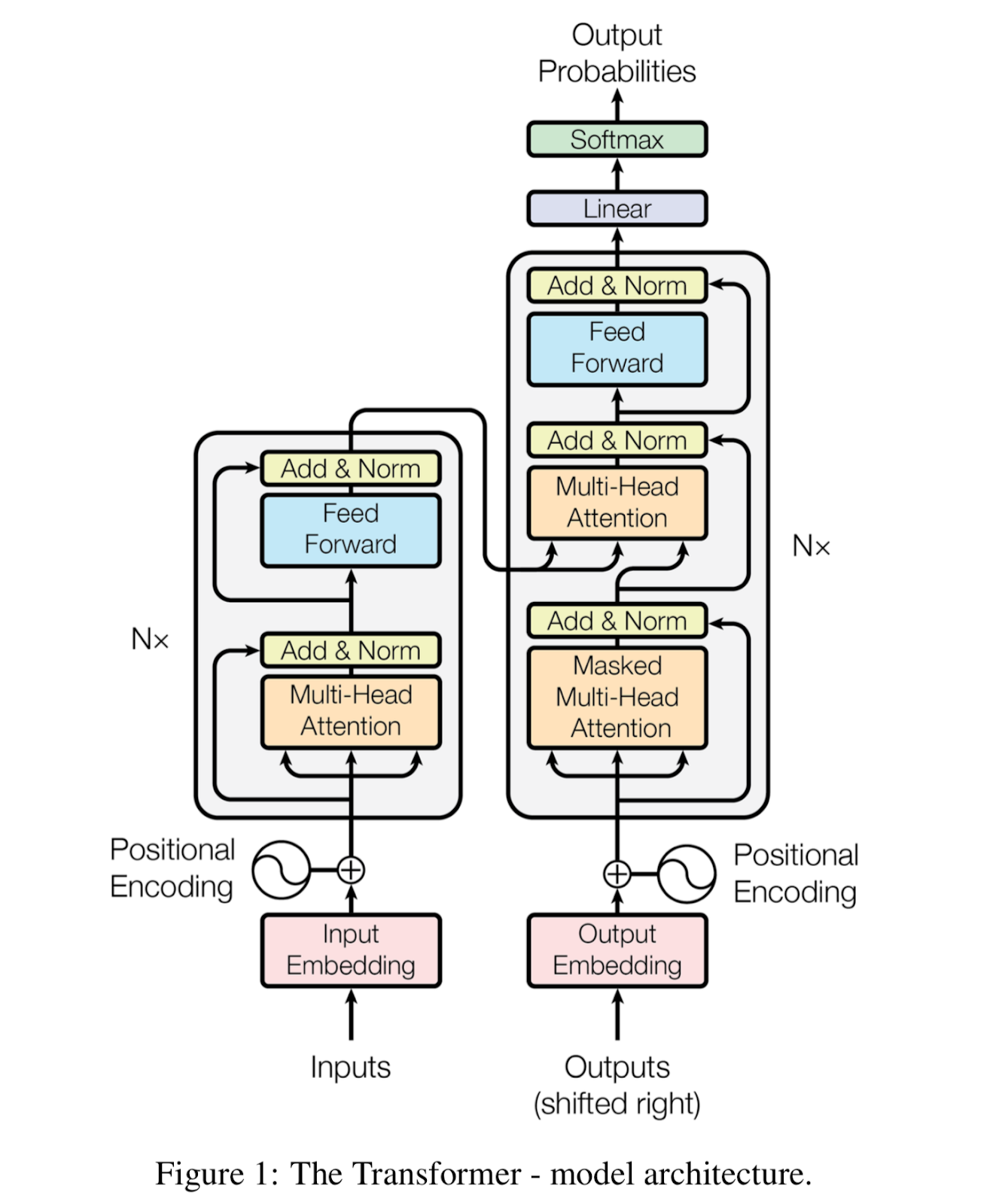
(There are of course many more details to GPT-3’s underlying technology. Since Interconnected caters to a wide range of readers, I won’t belabor all the details here. I’d encourage readers who are technical to read the GPT-3 paper, which lays out all aspects of the model, including algorithm, architecture, training process, evaluation, limitations, and ethical implications.)
GPT-3 is also not open sourced. Instead, the model’s abilities are exposed through an API layer that can be controlled. OpenAI’s justification is to limit malicious use of the model; if someone is abusing GPT-3 for nefarious purposes, OpenAI can turn off that user’s access to the API. Given just the limited examples of “magical” things that hobbyists have produced using GPT-3 -- from business writing and poetry, to designing a website and other forms of simple coding -- I think this approach is well-justified, even though it goes against my default position that always prefers open source.
This approach is not without its critics. When GPT-2 was first released, it was heavily criticized, both externally by other AI researchers and internally by OpenAI employees, for being not open sourced. These critiques also have merit: openness and transparency are important for other researchers to reproduce the technology. After all, good results can always be hard-coded and human-generated on the backend. OpenAI eventually open sourced GPT-2, as a public repository that is archived, after it felt comfortable that the model won’t be abused. I expect GPT-3 to follow this measured path to eventually becoming open sourced.
Money Can Solve (a lot of) Problems
Money can’t solve all our problems, but in the case of GPT-3, it has solved a lot of problems. In this context, money means cloud computing resources to train the model, where the larger the model and training dataset (both of which are very large for GPT-3), the more expensive it is to compute.
Broadly speaking, the path to developing AGI (artificial general intelligence) falls in one of two camps. One end of the research believes that Deep Learning is not the ultimate technique and more innovation is necessary. The other end believes that the necessary techniques are all available, so the focus should be on how to put them together and scale their training process and production deployment. More succinctly, the former thinks more time is needed to create better techniques, the latter thinks more money is needed to scale the current Deep Learning techniques.
According to this MIT Technology Review profile of OpenAI, the group’s strategy squarely falls in the “more money” camp. That’s why it has a rather bizarre corporate structure that’s a hybrid of a nonprofit and a normal VC-backed startup, but the investors’ returns are capped at a certain multiple -- 100x for the earliest round of investors. Microsoft also invested $1 billion in OpenAI with a preferred partnership to use Azure’s cloud infrastructure, as Microsoft works to develop its own AI supercomputer for its cloud offering.
(Aside: this partnership was quite a coup for Microsoft and to the detriment of Google in particular, given that GPT-3’s theoretical foundation, known as the transformer architecture, originated from Google. Google has also been developing its special-purpose Deep Learning hardware, the TPU (tensor processing unit), to differentiate GCP as the most capable AI cloud on the market. Google of course owns DeepMind, the other AGI company, so forging a partnership with OpenAI may even be a conflict of interest. For what it’s worth, Satya Nadella was openly bullish about GPT-3 during Microsoft’s most recent earnings call when talking about Azure. Whether OpenAI will help propel Azure to become the market-leading AI cloud or will Google maintain its technical advantage is a competitive dynamic worth watching.)
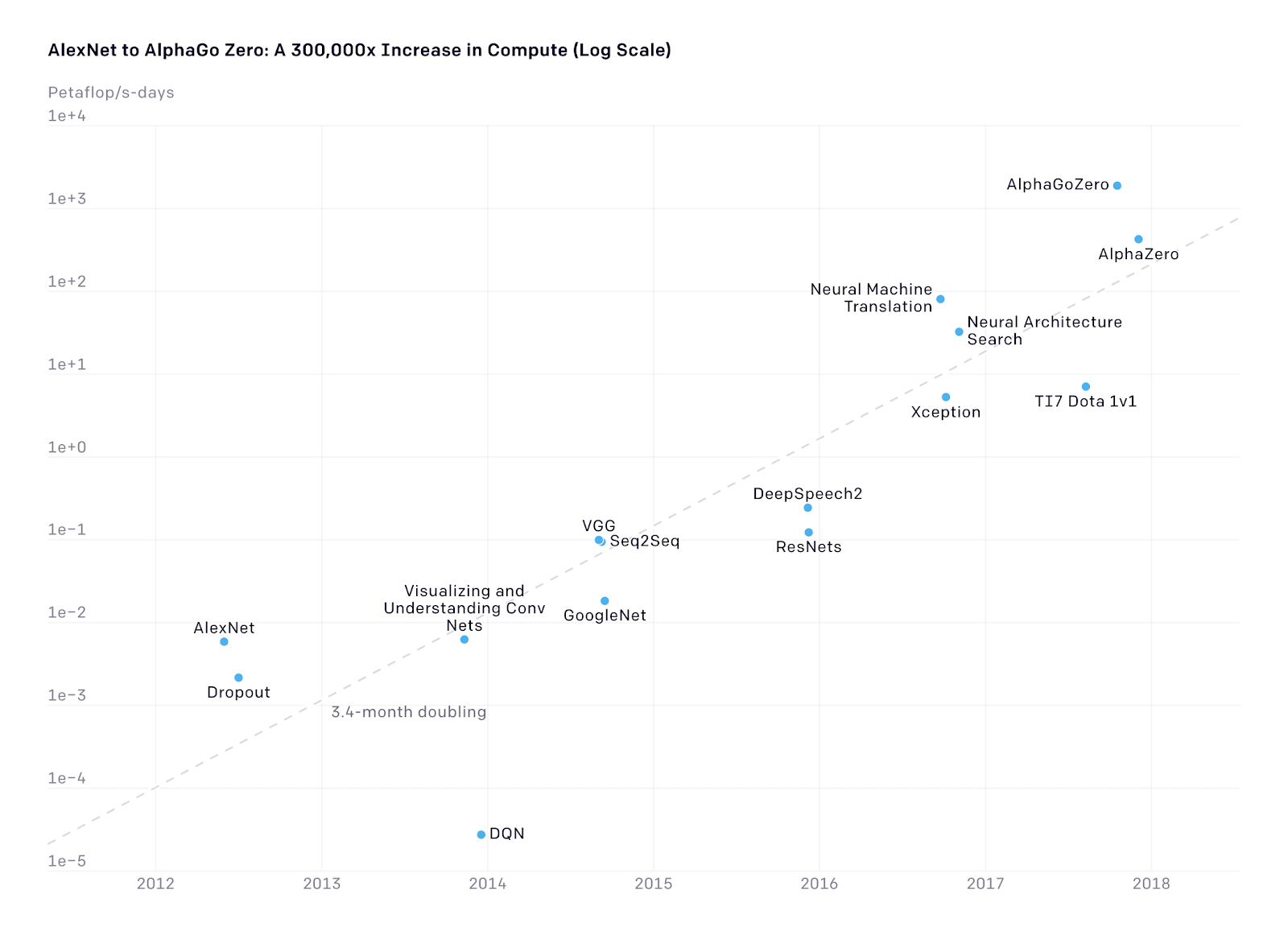
That $1 billion Microsoft money is rumored to be a split between cash and Azure credits. Regardless of which form the money comes in, OpenAI could use it and is using it. GPT-3 is estimated to have a memory requirement of more than 350GB and a training cost of more than $12 million. That’s likely the cost of a single round of training. Most models go through several rounds of training to achieve good results. Training GPT-3 three or four times could easily sink around $50 million, and that doesn’t include the cost of data cleaning and pipelining that usually goes into preparing a model for training.
OpenAI has done some interesting research on the connection between the amount of compute used and progress in AI (though perhaps just to support its “more money” approach). Since 2012, the amount of compute used in the largest AI training exercises (e.g. AlphaZero) has been doubling every 3.4 months. The research compares and contrasts this finding with Moore’s Law, which observes the doubling of the number of transistors on a chip every two years. This comparison is only useful to the extent that while Moore’s Law may be reaching its limit, AI computing advancement is far from slowing down. And much of this advancement is focused on parallel computing (i.e. efficient use of multiple chips processing workloads at the same time) and creating more special-purpose AI chips (e.g. TPUs or Tesla’s Full-Selfing Driving chip, which I’ve written about before), thus it is not directly constrained by Moore’s Law either.
I have a pragmatic attitude towards AI (and most things) and don’t have a strong opinion between the “more time” vs “more money” approach. If it’s working, it’s working.
It looks like GPT-3 is definitely working. Even if OpenAI’s observation and development strategy turn out to be half true, we will see future generations of GPT advance rapidly within the next five years.
Time and Expertise is Premium
So what is there left for humans to do? Plenty, but differently.
What AI models, like GPT, do to language understanding and state-of-the-art computer vision models do to visual understanding is the continuous commoditization of rote memorization (X is Y) and basic pattern matching (when X happens, Y usually happens), where the value approaches zero. Thus, any task that falls in one of these two broad categories that is currently done by human beings will be done more by AI.
We can get a hint of which industries GPT-3 may impact in this way, just by looking at the initial list of beta users:
- Algolia (search engine)
- Koko (mental health and emotional well-being via chat)
- MessageBird (customer service via text or voice)
- Sapling (HR and operations processes)
- Replika (mental health bot that keeps you company)
- Quizlet (online education via flashcard quizzes)
- Casetext (legal research)
- Reddit (public discussion forum)
- Middlebury Institute (higher education, known for having one of the top foreign language study programs in the world)
This list of companies and institutions may seem to cover a wide range of unrelated use cases, but they all have an element of memorization or basic pattern matching to their workflow that can be standardized by a well-functioning AI model to ensure consistency and quality. Furthermore, the GPT-3 paper revealed that while training the model was expensive (prohibitively so for most companies), producing inferences (aka results) from the trained model is cheap and consumes little energy. Thus, from a cost-efficiency perspective, companies will be incentivized to build their services on top of something like GPT.
What all this means, I believe, is that there will be a premium for the one thing that requires more time, but not necessarily money, to acquire: deep domain expertise.
Vitalik Buterin, the creator of the Ethereum blockchain, captured this possibility well in this tweet:
I can easily see many jobs in the next 10-20 years changing their workflow to "human describes, AI builds, human debugs". https://t.co/96ZSNr0YoN
— vitalik.eth (@VitalikButerin) July 17, 2020
What’s implicit in a “human describes, AI builds, human debugs" future is that the human must have enough expertise built over time to know “how to describe” a problem and “what to debug”. What this also means is that the very notion of “domain expertise” will become more niche and specific.
Knowing how to onboard a new employee may not be that valuable; knowing how to onboard a junior engineer two years out of college, so she can be productive within one month of starting will be. Knowing how to set up a standard cloud environment may not be that valuable; knowing how to troubleshoot a cyber attack that brought your infrastructure down will be. Knowing how to translate the basic meaning between two different languages may not be that valuable; knowing how to parse the signals and connotations that may get lost in a standard translation will be. etc. etc.
This future will reward people who can (and will) spend the time and energy to deeply understand something, and do so continuously over time. If I don’t continue to spend time reading, thinking, and understanding the intersections between technology, business, and geopolitics or the relationships between the US and China, regulators and companies, etc., Interconnected will be written by GPT-15 one day.
Of course, that leaves the big, hairy question of what happens to people who can’t (or won’t) spend the time and energy to develop expertise in something. A universal basic income should probably be in the picture to ensure basic sustenance and survival. Though that’s likely not enough to incentivize everyone to develop niche expertise, which requires not just time and survival, but internal motivation.
Ethics: A Humanity-Scale Challenge
One challenge around AI that most certainly would need more time than money to solve is ethics. The challenge isn’t on a company-scale or national-scale, but humanity-scale. While developers of AGI, like OpenAI, are fond of analogizing this eventuality to a “utility” that will just flow seamlessly in people’s lives, like electricity, the analogy falls apart pretty quickly. For one, electricity does not make decisions; it’s a straightforward source of power. AI, even the relative dumb, non-general ones we use today, makes decisions all the time, both for itself and for the humans it interacts with (see TikTok).
Tackling this challenge requires cross-border, cross-disciplinary, and cross-cultural collaboration. In a recent paper, academics from Cambridge and Beijing specifically advocated for more cross-culture cooperation on AI ethics and governance, while warning against the barrier that frosty relations between the AI superpowers -- US, China, and EU -- could erect.
To OpenAI’s credit, it recognizes that its work has a global impact and its audience is not just Americans and Europeans, but also Chinese. It’s not an accident that the OpenAI charter, the company’s overarching organizing principle and mission statement, has a Chinese version and no other language. Both the benefits and drawbacks of AI, AGI in particular, will be distributed and borderless, whether we like it or not.

As a pragmatist, I do believe for some necessities, it makes sense for countries to be self-sufficient and less connected with other countries. It is precisely the lack of self-sufficiency in medical supplies and devices that partially put the U.S. on its heels during the initial spread of COVID-19. It is precisely the lack of self-sufficiency in semiconductor design and manufacturing that is partially (or completely) hobbling Huawei and related tech sectors in China.
But for humanity-scale challenges like the ethical use of AGI, cross-border and cross-cultural cooperation is a necessity, not a nice-to-have. Money will likely get AGI to a level that will create a litany of difficult ethical challenges, as OpenAI has already demonstrated with GPT-3. However, time isn’t exactly on our side, if we don’t learn to cooperate soon.
These are obviously big problems that no single blog post can resolve. Until countries come together in the way those AI researchers from Cambridge, Beijing, and other places do, all I can do is just patiently waiting for my beta access to GPT-3.
If you like what you've read, please SUBSCRIBE to the Interconnected email list. New posts will be delivered to your inbox (twice per week). Follow and interact with me on: Twitter, LinkedIn.
GPT-3:时间与金钱的抽象
不管炒作与否,GPT-3,OpenAI最新的自然语言AI模型,自从两个月前发布后就一直在我的脑海里沉淀。在这篇文章里,我将对它在科技、商业和地缘政治的交叉点上的各层意义进行一些公开的思考。
不是故意装有哲理,但我认为GPT-3是时间和金钱之间关系和权衡的一个美妙的抽象。(别担心,这不是机器在说话。仍然是我,这位人类作者在写,而不是GPT-3。)
GPT-3概括
简单而言,GPT-3是OpenAI的第三代自然语言处理模型,上一代既是GPT-2,发布于2019年初。GPT-3有1750亿个参数,而GPT-2仅有15亿个参数。在深度学习AI的世界里,如果一个模型有更多的参数,它就更大、更复杂,并且通常会产出更好的结果。这么看GPT-3比GPT-2大100多倍。GPT-3还训练在一个更大的数据集上——来自“普通爬网数据集”的近万亿字,该数据集从整个互联网上爬下来的,数据公开为科研所用。同样,在深度学习AI中,用更多的训练数据通常会产生一个更好的模型,从该模型中产出的结果也会更好。今后还会有GPT-4,5,6等,比GPT-3更强大。
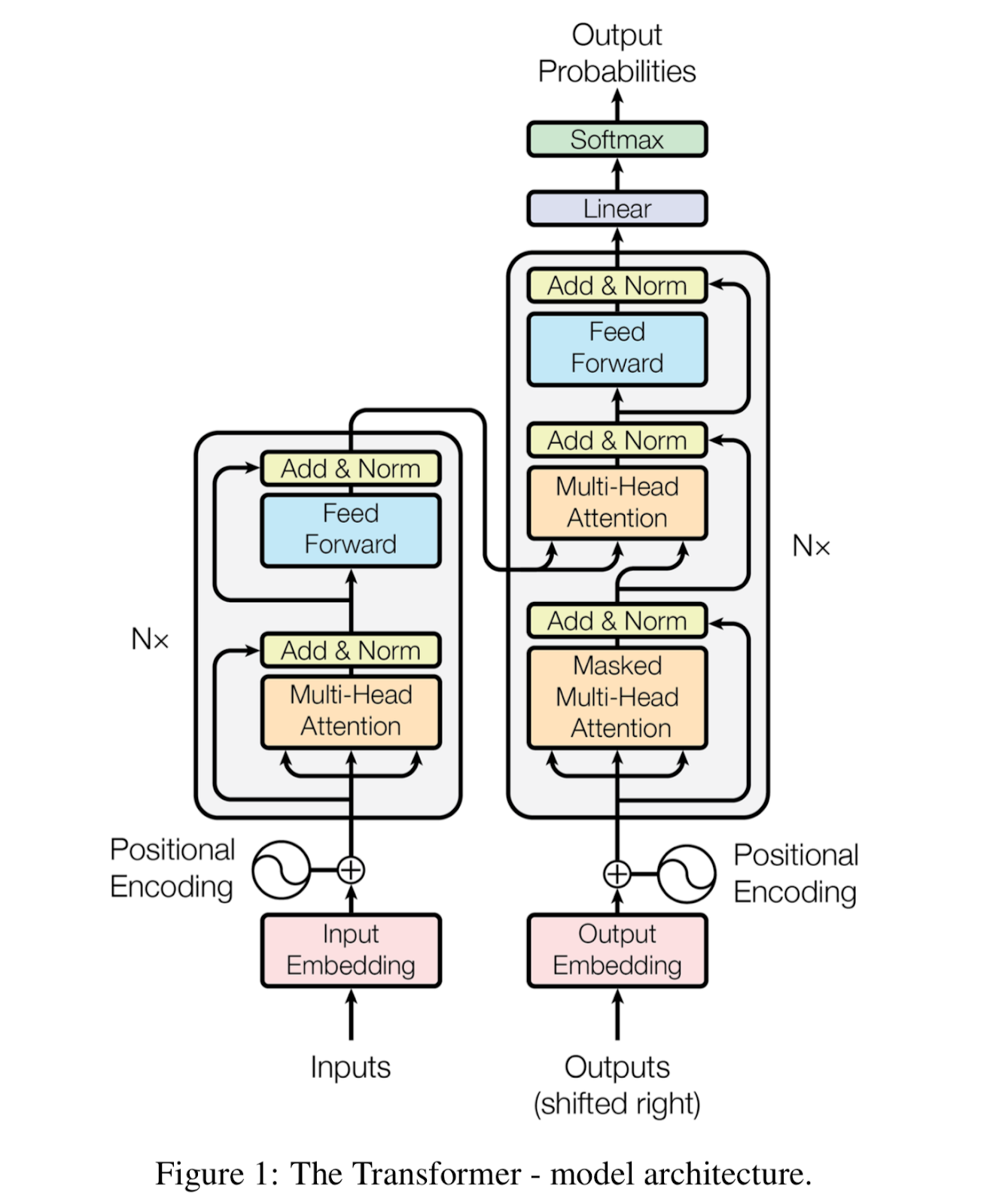
(GPT-3的整体技术还有很多细节。由于Interconnected的读者背景广泛,我就不在这里详细讨论所有细节了。我鼓励有技术背景的读者看看GPT-3的论文,里面阐述了算法、构架、训练过程、评估、限制和道德含义的许多方面。)
GPT-3同时还不是开源的。模型的功能通过一个可控的API层去应用。OpenAI的理由是限制恶意使用模型的行为;如果有人出于恶意滥用GPT-3,OpenAI可以关闭该用户对API的访问。考虑到许多业余爱好者已经用GPT-3做出各种各样“魔术般”的事情——从商业写作和做诗,到设计网站和其他简单代码——我认为这种做法是合理的,尽管它违背了我一贯对开源的倾向。
有很多人批评这种做法。当GPT-2首次发布时,它受到了来自外界AI研究人士和内部OpenAI员工的严厉批评,因为它不是开源的。这些谴责也有它的道理:开放与透明在学术研究里是至关重要的,因为需要复制和核实所有技术的成果。毕竟,好的结果总是有可能用hardcore或在后台人为手动来生成的。OpenAI最终将GPT-2开源了,现在是个已被归档的公共repo,因为它判断模型不会被滥用。我预期GPT-3也会遵循一个类似的过程,最终被开源。
钱可以解决(很多)问题
金钱解决不了所有的问题,但在GPT-3这个例子中,它解决了很多问题。金钱在这里代表的是训练AI模型的云计算资源,模型和训练数据集越大(对GPT-3来说这两者都非常大),计算成本就越高。
广义地说,发展AGI(人工通用智能)的道路分为两大阵营。一个阵营认为,深度学习不是终极技术,还需要更多的创新。另一个阵营认为,所有必要的技术都有了,重点在于如何将它们组合起来并扩展模型的训练和生产部署的效率。更通俗点说,前者认为需要更多时间来创造更好的技术,后者认为需要更多钱来扩展已有的深度学习技术。
根据MIT Technology Review对OpenAI的报道,该集团的战略方针完全属于“更多钱”阵营的。这可能也就是为什么它有个相当奇特的公司结构,一个非营利组织和一个普通风投支持的创业公司的混合体,但投资人的回报率有一定的上限——最早一轮投资人的上限是100倍。微软还给OpenAI投资了10亿美元,包括与Azure云基础设施建立优先合作伙伴关系,有助于微软正在为自己的云产品开发的AI超级计算机。
(旁白:鉴于GPT-3的理论基础,即变压器架构(transformer architecture),源自谷歌,微软能拿到这个伙伴关系,也算是大赢家了,同时也对谷歌有商业上的损害。谷歌也一直在开发自己为深度学习特制的硬件TPU(tensor processing unit),企图把GCP变成市场上功能最强大的AI云。谷歌当然也拥有另一家AGI公司,DeepMind,所以与OpenAI建立合作关系很可能有利益冲突。值得一提的是,微软CEO Satya Nadella在最近的季度财报电话会议中在谈论Azure时公开赞赏了GPT-3的进步。OpenAI会不会帮助Azure成为市场领先的AI云,还是谷歌会保持自己的技术优势,是个值得关注的竞争动态。)
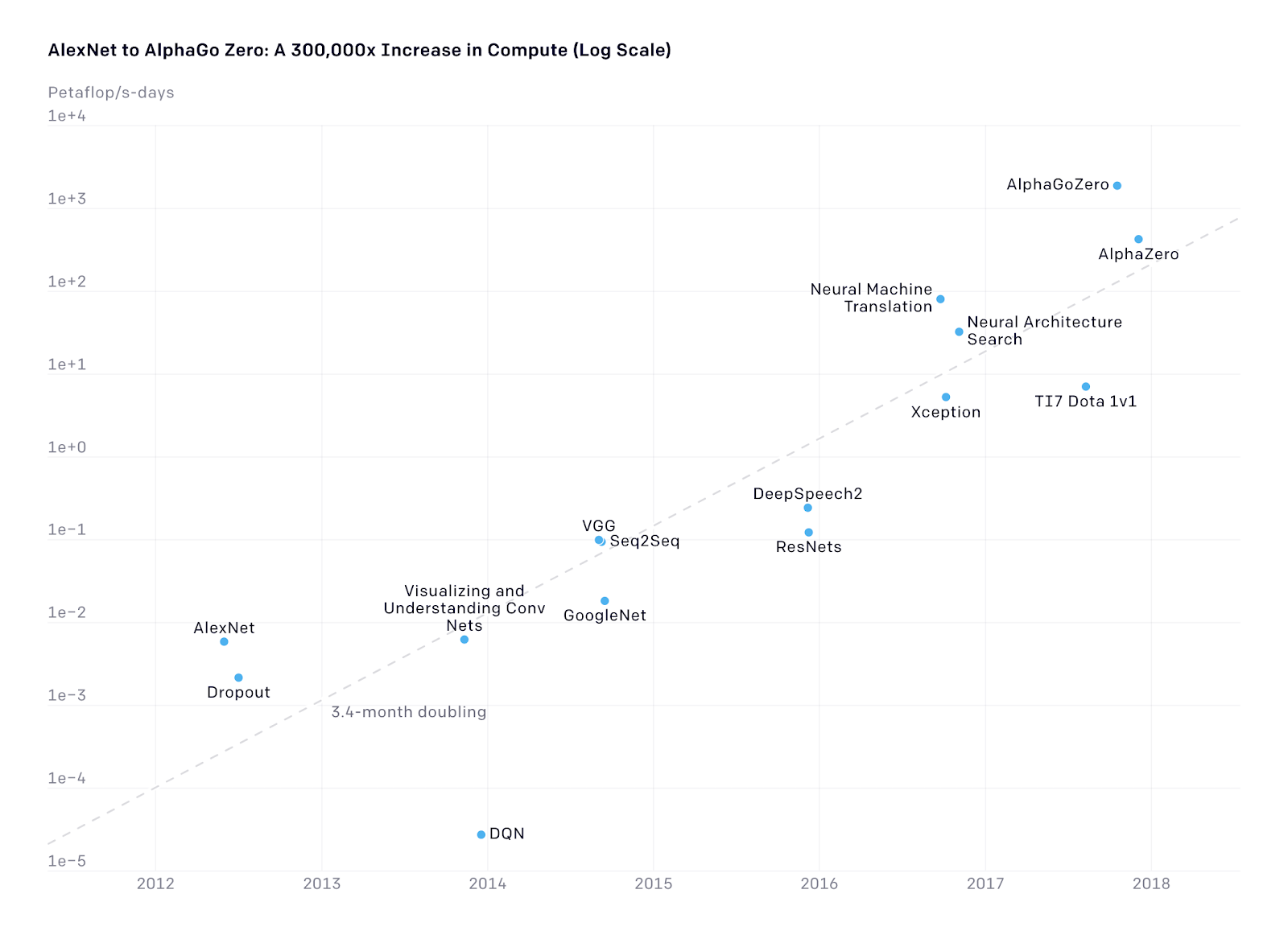
据传,微软的10亿美元投资一部分现金,另一部分是Azure credits。不管这钱是以何种形式流入,OpenAI都用得上它,也正在积极用它。据估计,GPT-3的内存需求超过350GB,训练费用超过1200万美元。这很可能仅是一轮训练的成本。大多数模特都要经过几轮训练才能取得好结果。假设GPT-3进行了三到四轮的训练,就会轻松地烧到5000万美元左右,这还不包括通常必须做的准备工作,如数据清理和数据管道搭建的成本。
OpenAI做了些有意思的研究,关于计算资源投入和AI的进展之间的关系(也许只是为了支持它“更多钱”的做法)。自2012年以来,在最大规模的AI模型训练中(如AlphaZero)使用的计算量每3.4个月翻一番。研究里把这一发现与摩尔定律进行了比较和对比。摩尔定律既是芯片上的晶体管数量每两年翻一番的这个经典观察。这个比较的意义其实仅限于,虽然我们离摩尔定律的极限可能已经不远,但AI计算的发展离减缓还有很长一段路。而且这些进步主要集中在并行计算(即:高效利用多个芯片同时处理工作负载)和创造更多专用的AI芯片(如TPU或特斯拉的全自动驱动芯片,这个话题我之前也分析过),因此发展也不直接受摩尔定律的约束。
我对AI(以及大多数事情)的态度是很务实的。在“更多时间”与“更多钱”这两种方法之间没有很强烈的看法。好用就是好用。
看起来GPT-3的确是好用的。就算OpenAI的观察和开发战略仅仅实现一半,未来几代GPT在这五年内也会有飞速的发展。
时间与专业知识最值钱
那人类还能做什么呢?很多,但不同的事情。
像GPT这样的AI模型对语言理解和最先进的机械视觉(computer vision)模型对视觉理解的深远影响就是:死记硬背(X是Y)和基本模式匹配(X发生时,Y通常也发生)的价值会继续降低,往零走。因此,任何属于这两大类的工作,目前是人做的以后更多都会由AI来做。
通过看看GPT-3的最初beta用户列表就可以洞察出它对哪些行业会有影响:
- Algolia(搜索引擎)
- Koko(聊天式的心理健康服务)
- MessageBird(通过短信或语音提供客服)
- Sapling(人事和公司运营流程)
- Replika(与你相伴的心理健康机器人)
- Quizlet(抽认卡形式的在线教育)
- Casetext(法律法案研究)
- Reddit(公共论坛)
- Middlebury Institute(高等教育,以世界顶尖的外语教育科目闻名)
这些公司和机构覆盖了一大片看似并不相关的行业和用例,但它们都有一些需要死记硬背或基本模式匹配的元素在内,所以可以通过功能良好的AI模型进行标准化,来确保一致性和质量。此外,GPT-3论文里揭示了虽然模型的训练费用昂贵(对大多数公司来说高不可及),但从训练好的模型中得出推论(可以理解为结果)其实很便宜,消耗的能源很少。因此,从成本效益的角度来看,会有很多公司有动力将自己的服务构建在GPT的基础上。
我相信所有这一切意味的是,今后一个人最有价值的东西就是需要时间(但不一定需要钱)才能累积出来的东西:领域和专业知识。
以太坊区块链的创建者Vitalik Buterin在这条推特中很好地形容了这种未来:
I can easily see many jobs in the next 10-20 years changing their workflow to "human describes, AI builds, human debugs". https://t.co/96ZSNr0YoN
— vitalik.eth (@VitalikButerin) July 17, 2020
在“人类描述、AI构建、人类调试”(human describes, AI builds, human debugs)的未来里,隐含的意义是:人必须拥有足够的专业知识与时间和经验的累积去知道“如何描述”一个问题和“该调试什么”。这也意味着“领域专长”的概念将变得更加细化和具体。
知道如何安排上任一名新员工可能没那么有价值;知道如何安排上任一名大学刚毕业两年的年轻工程师,让她在开始工作一个月内就有生产力,将会非常有价值。知道如何搭建一个标准的云环境可能没那么有价值;知道如何排除导致基础设施瘫痪的网络攻击将会非常有价值。知道如何在两种语言之间翻译基本含义可能没那么有价值;知道如何解析基本翻译中可能流失的潜在意义和内涵将会非常有价值。等等。
这个未来将奖励那些能够(也愿意)花时间和精力深入理解某件事,并且随着时间的推移不断去学习的人。如果我不继续花时间阅读、思考和理解科技、商业和地缘政治之间的关系,或者美国与中国、监管机构与公司等之间的关系,《互联》总有一天会由GPT-15撰写。
当然,这就留下了一个大而棘手的问题:那些不能(或不愿意)花时间和精力来发展自己某方面专业知识的人今后会怎么样呢?一个普及基本收入(UBI)制度可能应该被实施,以确保基本生计和生存。虽然这也不足以激励每个人发展自己的专长,因为这不仅需要时间和生存,还需要人内在的动力。
道德:全人类的挑战
围绕AI的一个大挑战,也是需要更多的时间而不是金钱才能解决的就是它的道德问题。这个挑战不仅是某公司或某国家的,而是全人类的。虽然像OpenAI这种开发AGI的公司喜欢把AGI比喻成像电一样的一种未来的“公共资源”,将在人类生活中无缝流动,但这种比喻意义有限。最直观的看,电不能做决定。它就是一种能源。AI,即使是我们今天使用的相对愚蠢的AI,已经一直在为自己和与之交流的人类做决定(比如TikTok)。
应对这一挑战需要跨国界、跨学科和跨文化的合作。在最近的一篇论文中,一组英国剑桥和北京的学者特别主张在AI的道德和治理方面需要更多的跨文化合作,同时还警告美国、中国和欧盟这三个AI超级大国之间的冷淡关系可能会产生的合作障碍。
值得称赞的是,OpenAI已经认识到自己的作品具有全球影响力,其受众不仅是美国人和欧洲人,还有中国人。OpenAI章程,也就是公司的首要组织原则和使命声明,就有中文版本而没有其他语言,这并非偶然。AI的优点和缺点,特别是AGI,将是分布的,无边界的,无论我们人类愿不愿意。

作为一个比较务实的人,我其实认为在有些必需品方面,各国实现自给自足减少与其他国家的关联是有道理的。正是由于缺乏医疗用品和设备的自给自足,才导致美国在COVID-19疫情最初开始扩散的过程中步履蹒跚。正是半导体设计和制造业缺乏自给自足,才导致部分(甚至全部?)的阻止了华为以及中国相关科技行业的发展。
但对于全人类规模的挑战,如AGI的道德使用,跨国界和跨文化合作是必要的,而不只是一件可有可无的好事。钱可能会让AGI达到一定高的水平,从而产生一系列道德难题,正如OpenAI已经用GPT-3所证实的。然而,如果大家不尽快学会合作,时间就越来越少了。
这些巨大的挑战是任何一篇博客都无法解决的。在各国能学会像剑桥、北京和其他地方的AI研究人员那样走到一起之前,我也只能耐心等待做GPT-3的beta测试用户了。
如果您喜欢所读的内容,请用email订阅加入“互联”。每周两次,新的文章将会直接送达您的邮箱。请在Twitter、LinkedIn上给个follow,与我交流互动!