
One of the most frequently discussed topics related to COVID-19’s multi-dimensional impact is the dramatic increase in “work from home” (WFH). A popular extension of that discussion is the various tools, applications, and technologies that are being used to make work from home...work! As it turns out, almost all of the commonly-used technologies for this purpose are either directly provided by large cloud platforms or run on one of them.
I’ve written quite a bit of analysis before on “stress testing” the various cloud platforms to assess their relative strengths and weaknesses, from looking at their other core businesses as a proxy, to the breadth and quality of their global data center coverage. Widespread WFH and demand for online entertainment and education, as more adults and children stay home, is giving every cloud an unprecedented stress test as we speak.
How are they faring so far?
[NOTE: if you are interested in more cloud-related analysis on Interconnected, please checkout the newsletter's Cloud Industry category.]
Azure Showing Cracks
Microsoft’s Azure is showing signs of weakness as demand surges for its various collaboration and workplace products, from Office 365 to Windows Virtual Desktop to Teams (the workplace messaging service that competes with Slack). One misleading headline that’s been pushed out by Microsoft and unfortunately picked up by various tech media outlets, is the “775% increase” in Azure cloud service usage in geographical areas that are most committed to some form of social distancing or shelter-in-place policy.
I don’t blame the Microsoft PR team for pushing a positive narrative to make their products look good; that’s their job. But putting my analyst hat on, this narrative when not fully contextualized and understood, papers over cracks in the Azure infrastructure that are already showing.
First, this 8-plus-fold usage increase is limited to places where shelter-in-place is in full force as of the end of March, which at least in the United States, is only a small part of the country with densely populated urban areas: New York, California, New Jersey, Michigan, etc. Touting the percentage increase number is a classic trick of spinning massive growth out of a small or unknown base.
Second, just in March alone, multiple issues have occurred on various Microsoft cloud services: twice in just the last few weeks for European users of Teams, customers not getting the capacity they need in the US East Region, and XBox Live going down during a time when online gaming is surely surging. To put the timing in perspective, America and Europe only started taking COVID-19 seriously on a societal level in March. Parts of Azure began to fail almost as soon as people’s behaviors began to change.
Third, the way Azure has been dealing with and communicating about resource prioritization and changing service-level guarantees with free and paid-tier customers tells me that it has less extra capacity than what you might assume with a hypercloud provider. Yes, it’s definitely the right thing to do to prioritize capacity for any service or application that is supporting healthcare or other important efforts related to combating COVID-19, as is the case with PowerBI, Microsoft’s big data analytics tool. That being said, the other workarounds of “limits on free offers”, recommending “customers use alternative regions...that may have less demand surge”, and just encouraging “any customers experiencing allocation failures to retry…” indicate that there is little untapped resources to bring online to meet this demand surge. The only way forward is shifting existing resources around, keeping your paying customers happy, and forgoing the usual generosity for free users that can only happen in good times.

All these cracks, and we may see more in the future, are not surprising. As I’ve noted in previous data center coverage and “stress test” analysis, Azure’s 54 live regions which are mostly of single availability zone (AZ) in their design is an architectural flaw. It provides less redundancy and reliability than a multi-AZ set up (usually three AZs), which is the default in AWS, GCP, and parts of Alibaba Cloud. Since Microsoft’s other businesses are either hardware or office software, with the exception of maybe XBox’s gaming, it generally lacks operational experience in running “always on” services and preparing for unanticipated traffic surges.
And all this is happening on Microsoft’s own home-grown services running on its own cloud, not even third party services built on top of Azure.
(Note: in order to avoid possible legal liability caused by the "775% increase" headline, Microsoft filed this 8K report to the SEC to clear up its motivation.)
AWS Standing Strong
Meanwhile, there has been little news coming out of AWS. In this case, no news is good news. AWS also sells its own workplace enterprise software, like Chime (videoconferencing, messaging) and WorkSpaces (remote desktop), while running plenty of 3rd party ones that have become household names during the COVID-19 induced surge in WFH: Zoom, Slack, the Atlassian suite, to name a few. (Worth noting: Zoom also uses Azure and its own data centers; proportion of workloads is not clear.) AWS also backs many entertainment services that people can’t live without while stuck at home: Netflix, Hulu, Twitch (owned by Amazon), Fortnite (owned by Epic Games, a big AWS customer).
Perhaps most important of all, AWS is the infrastructure for Amazon.com, Instacart, DoorDash and many others, whose delivery of grocery, meals, and other goods have made them essential services in keeping the self-quarantined population alive.
It’s safe to say that AWS runs a much bigger, if not more critical, chunk of the digital world than Azure. AWS has previously developed comprehensive processes for preventing outages during natural disasters and unexpected events, perhaps due to its own epic outages from before. And looks like it’s holding up well so far under the current crisis.
Myth of Adding Capacity During COVID-19
As for the other clouds: GCP, Alibaba Cloud, IBM, Oracle, Tencent Cloud, etc., not much COVID-19 related outages have been reported thus far. That’s partly due to the reality that these cloud vendors combined still run a smaller portion of the Internet than AWS and Azure; they are not big enough to be stress tested on the same level.
The standard external response from any cloud vendor that’s under resource constraint, like Azure, is that it will add more capacity as quickly as possible. There is no way to know for sure how much extra capacity each cloud has or should have. But we do know what they normally do to increase capacity.
From a technical angle, there are only three options. You either (1) build additional data centers and networking, which takes years, or (2) rack up more servers into your existing data centers, or (3) use software to boost throughput, performance, or multi-tenancy capacity in order to squeeze more out of the existing hardware. Under COVID-19, where human movement is limited, manufacturing capacity is constrained, especially in Asia where much of the servers are made, and supply chain and shipping capacity are reduced, the only near-term option is software.
And when the technical options are all exhausted, the only thing you can really do is use financial incentives and disincentives to control, limit, or shift usage, which appears to be what Azure is doing.
The economics of a cloud business, much like insurance, count on uncorrelated risks.
So when these cloud vendors' PR departments try to calm your concerns with their "we are adding capacity" talking point, know that what they realistically can do is pretty limited.
At the end of the day, the economics of a cloud business, much like insurance, count on uncorrelated risks. Ideally, a platform runs many businesses with some unused capacity on reserve but not too much to be wasted, so when some businesses’ usages spike, they can use the extra capacity, and those spikes don’t lead to other businesses spiking too. If the spikes are related, it’s manageable as long as it’s anticipated, as is the case of e-commerce shopping holidays like Singles Day or Black Friday -- provision extra capacity ahead of time and simulate traffic surges to stress test.
Of course, we live far from an ideal world right now. When something like COVID-19 triggers many events all at the same time, many of which are impossible to anticipate, as a cloud platform, you either have the capacity or you don’t.
(This post was updated on April 2, 2020, after initial publication, with a link to Microsoft's 8K filing to the SEC regarding its "775% increase" blog post and a update/correction to AWS's own workplace software offering, which I failed to mention in the original version.)
If you like what you've read, please SUBSCRIBE to the Interconnected email list. New posts will be delivered to your inbox (twice per week). Follow and interact with me on: Twitter, LinkedIn.
Azure有裂痕,AWS很靠谱:COVID-19对云的压力测试
与新冠疫情对社会和经济影响相关的最热门的话题之一就是“在家工作”(Work From Home, WFH)的增加。这个话题的一个自然延伸就是讨论各种协助远程工作的工具、应用程序和技术。这些工具和云平台有着紧密的联系,目的常用的工具和软件要么由大型云平台直接提供,要么就在某个云平台上运行。
我之前写过很多关于“压力测试”各种云平台的分析,以评估它们的相对优势和劣势,一方面从它们母公司的其他核心业务做分析,另一方面看它们的全球数据中心覆盖的范围和质量。随着越来越多的成人和孩子都必须待在家里,广泛的WFH和对在线娱乐及教育的需求正在给每一个云带来前所未有的压力测试。
他们目前承受的如何?
【注:如果您对与云有关的分析感兴趣,请看《互联》的云行业文章分类。】
Azure已出裂痕
随着微软的各种办公协作服务产品的需求激增,从Office 365到Windows虚拟桌面到Teams(与Slack竞争的办公交流程序),Azure已经显示出一些裂痕和弱点了。微软最近推出了一个容易让人误导的宣传,不幸也被各种科技媒体买账了,那就是在某些地区使用Azure云服务的用量“增长了775%”,这些地域都是最积极实施为了避免疫情扩散而叫民众回家工作的地方。
我并不责怪微软公关团队为了给自己产品增光而推行这种说法:这是他们的工作。不过,我写这篇文章的目的是要作出客观分析,所以就不能断章取义,要实事求是地讲解Azure基础设施中已经出现的裂缝。
首先,这8倍以上的使用量增长仅限于那些在三月末已经执行庇护政策较好的地方,至少在美国,只包括了个别人口稠密的州和城市:纽约、加利福尼亚、新泽西、密歇根,等等。巧妙地用百分比增长数来说故事是一个经典手法,误导性很强,在不知道基数有多大多小时,是没有什么真正意义的。
第二,仅在3月份,各种微软云服务就出现了多个问题:欧洲的Teams用户在过去几周内出现了两次服务中断,美国东部地区的客户无法扩容获取所需的资源,XBox Live在网络游戏肯定暴涨的时期也出现故障。从时间上看,美国和欧洲在3月份才开始动员整个社会认真对待新冠疫情。也就是说,当人们一开始改变日常行为时,Azure的某些部分就开始翻车了。
第三,为了适应使用量增长的压力,Azure已经在调整免费和付费用户使用资源的优先级,以及更改服务级别和质量的承诺。这种适应方式告诉我,Azure内部的额外容量比想象的可能要少很多。Azure专门提高了对支持医疗或其他与治疗新冠疫情相关业务而使用的产品的优先级,这种政策当然是正确的。微软的大数据分析工具PowerBI就是个例子。但像“限制免费服务”、建议“客户使用需求激增较少的其他Region”和鼓励用户“遇到分配失败的时候就重试几次…”等其他解决办法表明,Azure系统里几乎没有还保留的资源可以立即上线满足激增的需求了。唯一的出路就是调整现有的资源,让付费客户满意,并放弃通常慷慨地为免费用户提供的资源。
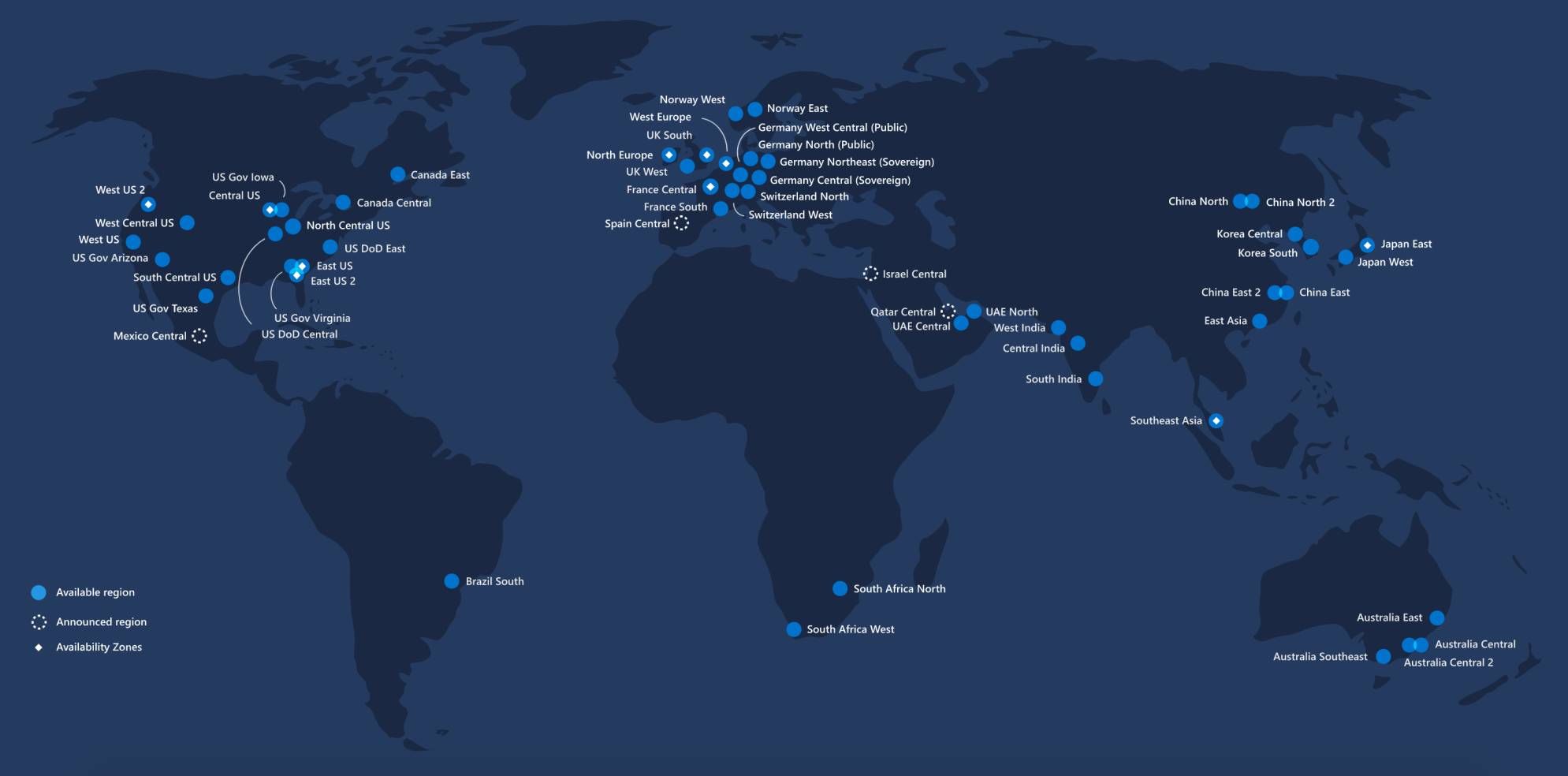
现有的这些裂缝(以后可能会更多),其实并不让人惊讶。正如我在之前的数据中心分析和“压力测试”分析文章中所指出的,Azure的54个Regions在设计上大多是一个AZ(Availability Zone),这种架构是有明显缺陷的。它的冗余性和可靠性远远不如多AZ设置(通常是三个AZ)来的好,这也是AWS、GCP和部分阿里云的默认设置。由于微软的其他业务除了XBox游戏之外要么是硬件,要么是办公软件,其团队缺乏运营“always on”的互联网服务和应对意外流量洪峰的实战经验。
而且,目前所有的问题都出在微软自己的应用程序里,在自己的云上,都还没轮到在Azure之上构建的第三方服务呢。
(注:为了避免“775%增长”这个标题可能会导致的法律责任,微软向美国证券交易委员会提交了这份8K报告来澄清自己的动机。)
AWS稳定如常
与此同时,AWS最近几乎没有什么新闻。没消息就是好消息。AWS也卖自己的办公企业软件,比如Chime(视频会议,短信)和WorkSpaces(虚拟桌面),同时也运营许多在新冠疫情爆发后的WFH热潮中已经家喻户晓的第三方办公软件:Zoom、Slack、Atlassian套件等等。(值得提一下:Zoom也用Azure和自己建的数据中心,具体的分工比例我们无从得知。) AWS还支持许多人们因为锁在家里而无法摆脱的娱乐服务:Netflix、Hulu、Twitch(Amazon旗下)、Fortnite(Epic Games旗下,是AWS的大客户)。
或许最重要的是,AWS是Amazon.com、Instacart、DoorDash和许多类似公司的基础设施,这些公司提供的食品杂货、膳食和其他商品的送货上门服务,已经使它们成为维持自我隔离人群生存而不可或缺的服务。
AWS比Azure占据的份额要大得多,服务的公司的业务也对社会更关键。AWS之前已经完善了许多避免自然灾害和意外事件带来的服务中断而应急的紧急措施和流程,可能因为自己以前也出现过大规模中断的事故。在当前的危机下,AWS的表现令人刮目相看。
疫情期间增加容量是个神话
至于其他的云厂商:GCP、阿里云、IBM、甲骨文、腾讯云等,到目前为止,与疫情相关的宕机报道并不多。在某种程度上看,这只是因为这些云的市场份额都远远小于AWS和Azure;它们的规模不足以在同一级别上被疫情导致的事件压力测试。
当一个公有云平台受到资源上的压力时(比如Azure),它的标准对外回应就是我们会尽快增加资源和容量。作为旁观者,我们无法确定每个云有多少额外容量或应该有多少。但我们知道他们通常如果需要扩大容量可以做些什么。
从技术层面来看,只有三种选择。可以(1)构建更多的数据中心和网络,这需要数年的时间,(2)把更多的服务器装入现有的数据中心,或者(3)使用软件来提高吞吐量、性能或多租户容量,从现有硬件中挤出更多的性能。因为新冠疫情的全球扩散,人员流动有限,制造能力也受到限制,特别是在亚洲(许多服务器都是在亚洲制造的),供应链和运输能力都有所减少,因此,近期唯一能解决问题的选择就是通过软件。
当所有技术选项都用尽后,唯一能做的就是使用各种费用的激励和抑制来控制、限制或转移云资源的使用。这似乎就是Azure正在做的事情。
云业务这门生意,就像保险一样,依赖于非相关的风险预测和控制。
所以,当这些云厂商的公关部门试图通过“我们在增加容量”这个字眼来平息你的担忧时,要明白他们实际能做的是相当有限的。
归根结底,云业务这门生意,就像保险一样,依赖于非相关的风险预测和控制。理想情况下,一个平台可以运行许多公司的业务,而且一直会有不多不少的备用容量,这样不会浪费太多。当某些公司业务的使用量突然激增时,它们可以使用备用容量,而这些激增不会导致其他公司的业务也激增。如果激增是相关的,只要是有预期的,也是可以好好处理的。光棍节或黑五这样的电商购物节就是这种现象。只要提前扩大容量,模拟流量激增以进行压力测试一般就可以过关。
当然,我们的现状离理想世界很遥远。当新冠疫情这种突发大事件同时触发许多其他事件时,其中有很多是无法预料的,作为一个云平台,你要么有资源,要么就没有,临时补是来不及的。
(这篇文章在2020年4月2日首发后有所更新,包括:微软提交给美国证券交易委员会的关于其“775%增长”的博客文章的8K申报文件的链接,以及纠正我在原版文章中没有提到的AWS原厂办公软件产品。)
如果您喜欢所读的内容,请用email订阅加入“互联”。每周两次,新的文章将会直接送达您的邮箱。请在Twitter、LinkedIn上给个follow,与我交流互动!