
(Disclosure: this post is *not* written by AI.)
With DALL·E, ChatGPT, and the overall hype around “generative AI”, every newsletter post on the Internet should probably start disclosing whether it is written by AI or not. I figured I might as well start the habit early!
Playing with ChatGPT over the weekend, the experience reminded me of a startup idea I pursued five years ago, when I was graduating from Stanford Law School. Back then, “chatbot” was enjoying its own hype – everyone was building a chatbot, or a framework or tool to let someone build chatbots. Instead of becoming a lawyer, I also wanted to build chatbots.
My idea was to build a chatbot that can answer people’s questions about their healthcare insurance plan. (After all, a healthcare insurance plan is just a straightforward contract, so all my chatbot has to do is “read” these contracts and spit out answers. How hard can this be, right?) So I built one using tools from Facebook and Microsoft. Building it was easy, many people resonated with the problem I was tackling, and demoing it to possible customers was validating, but the idea still failed. In the end, I tossed my code into a GitHub repo and called it a day.
I realized what made building a “health insurance chatbot” hard was not the chatbot part or the conversational AI part. It was the health insurance domain part and the serious responsibilities that came with that domain. Getting a user question “wrong” about her insurance has much more serious financial and health consequences than a high school student’s homework. But if the chatbot does not try to get the answer “right” and simply gives boilerplate answers to avoid liabilities, then it is not useful.
As I played around with ChatGPT, asking it health insurance questions, the same set of challenges around AI’s awkward relationship with domain expertise – more specifically domain knowledge (things you know that others don’t) and domain liability (things you suffer consequences for if you get it wrong) – is evolving.
Domain Liability
On the technical front, what ChatGPT can do today has been nothing short of impressive. The model that it is based on, GPT-3 (as in the 3rd major version of GPT), was only released two years ago. Building on GPT-3.5 (GPT’s newest, presumably best, version), ChatGPT’s conversational capability on any topic under the sun is stunning and can even feel like a “human”.
OpenAI is no doubt aware of the “lack of domain expertise” challenge I noted. That’s why when I asked ChatGPT about how to save money on prescription drugs if my insurance is with UnitedHealthcare (a common question), its answer was less prescriptive and more descriptive:
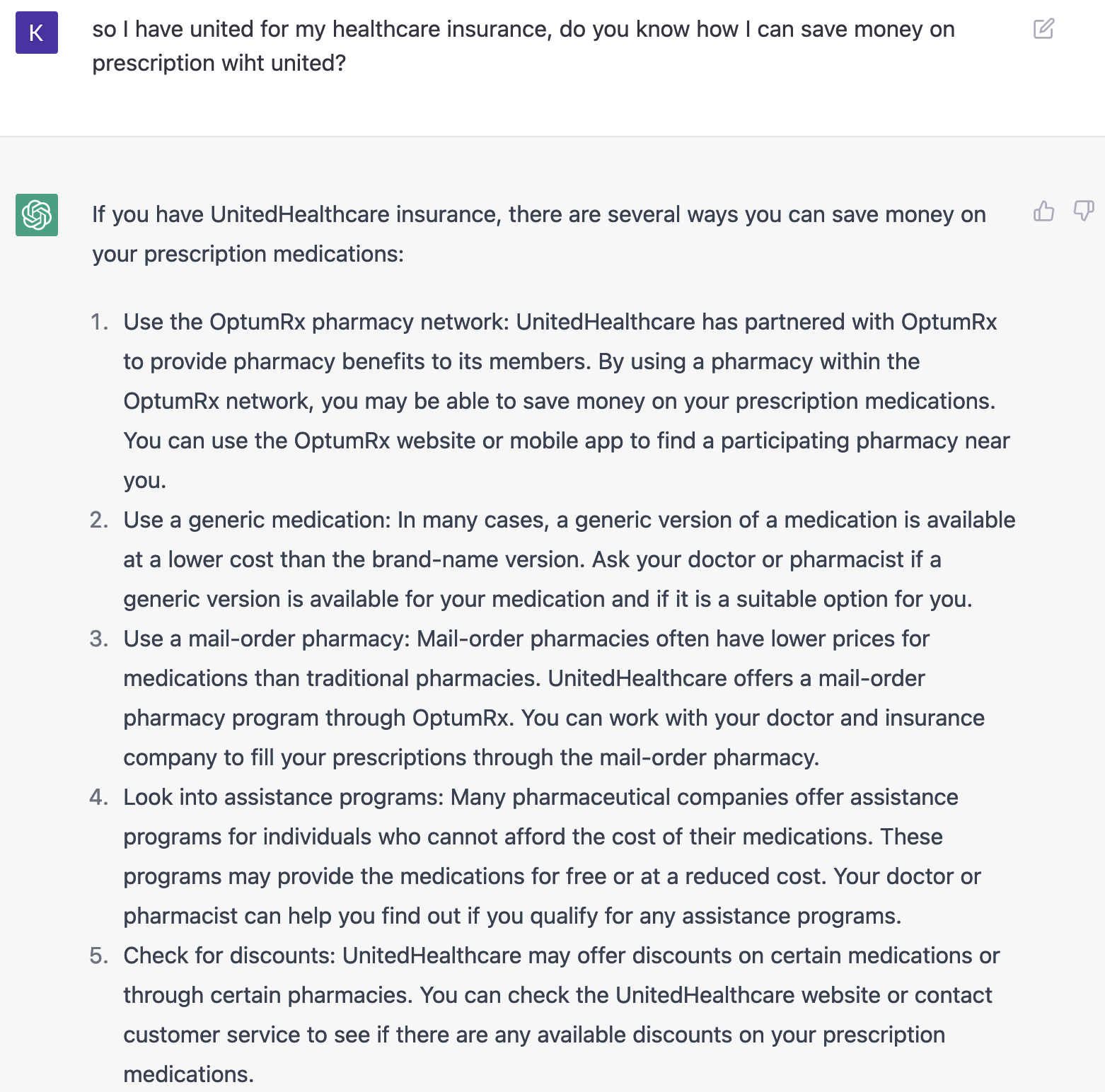
However, I was still impressed by this answer because it included some UnitedHealthcare specific information, like the OptumRx pharmacy network. It was not completely generic just to avoid being “wrong” and incurring liability.
Since ChatGPT was trained on reams of data from crawling the entire Internet, including probably UnitedHealthcare’s website, there are likely vectors in its neural network model that made the connection between “UnitedHealthcare” and “OptumRx pharmacy network”. What’s noteworthy here is that ChatGPT felt “confident” enough to generate an answer with this connection included.
Whatever default parameters OpenAI has set for ChatGPT, it is skillfully walking a fine line between “being useful” while avoiding domain liability. It is able to walk this fine line, because this version of GPT is trained on all the domain knowledge that is crawlable from the Internet up to September 2021. It effectively knows everything that is knowable on the Internet up to that date. Since healthcare in general does not change frequently, I got an answer with more specific details than I would’ve expected from a “confident” AI. (An interesting thought experiment would be if healthcare legislations changed in early 2022, whether ChatGPT would give me the same answer with the same level of details.)
This begs the question: what is still domain knowledge and what would become of it?
Domain Knowledge
There is a lot of domain knowledge from every field and industry published on the Internet. Paradoxically, the moment a piece of information is published online, it ceases to be within a special domain and is effectively commoditized.
As long as AI organizations like OpenAI continue to spend money to crawl the Internet and train models like GPT, the realm of what can be truly considered “domain knowledge” will continue to shrink. In my view, in that future (which feels like an inevitability), there will be three types of domain knowledge still left standing that are off limits to AI – proprietary, interpretative, and creative.
Proprietary domain knowledge can be simply defined as information that is useful and not crawlable. In the context of my failed health insurance chatbot, the proprietary domain knowledge would be the hundreds of thousands of different health insurance plans from different insurance companies – not crawlable and all locked up in paper form or PDFs.
Interpretative domain knowledge is new knowledge generated from connecting the dots within or between different domains, which requires a sufficient level of knowledge in multiple domains to begin with. Again, in the context of my failed health insurance chatbot, the interpretative domain knowledge would be the range of cost a patient using health insurance X in hospital Y doing procedure Z may incur. Arriving at an accurate interpretation of this scenario requires some legal knowledge of how the insurance contract works and some healthcare industry knowledge of how that insurance plan interacts with different hospital’s rates for different procedures. None of that is crawlable.
Creative domain knowledge is all the things that human beings have yet to create in any domain, thus by default not crawlable. This category is often associated with pure creativity in the form of art, music, writing, movies, etc. But it can be really anything that is sui generis. Once again, in the context of my failed health insurance chatbot, if a new financial instrument was invented by the industry that completely changes how premiums and deductibles interact, there would be no way for my bot or ChatGPT to know about it, recreate it, or anticipate it.
When GPT-3 was first released in beta in mid-2020, I thought it was a fascinating abstraction of time vs money. Specifically in a future with more powerful AI, there will be a premium on the one thing that requires more time, but not necessarily money, to acquire: domain expertise. Back then, Vitalik Buterin of Ethereum fame encapsulated this future well in this tweet:
I can easily see many jobs in the next 10-20 years changing their workflow to "human describes, AI builds, human debugs". https://t.co/96ZSNr0YoN
— vitalik.eth (@VitalikButerin) July 17, 2020
Fast forward to today with GPT-3.5, this dynamic has been accelerated, though the fundamentals are the same. Noah Smith captured the human-AI dynamic succinctly in his “sandwich” workflow:
“This is a three-step process. First, a human has a creative impulse, and gives the AI a prompt. The AI then generates a menu of options. The human then chooses an option, edits it, and adds any touches they like.”
Whether it is “human describes, AI builds, human debugs” or “human sandwiching AI”, the assumption is that in order for this human to use AI productively (and not be superseded by AI), she must know something the AI does not (proprietary), understand something the AI cannot (interpretative), or make something the AI does not know about yet (creative).
Thus, whether you believe GPT will be our overlord soon or GPT is still too stupid to threaten human civilization, the only actionable thing you can do (if you are a human) is to keep deepening your domain expertise and create new knowledge.
That’s the only way to see through the BS, whether it is human-generated or AI-generated.