
I’m about to board a plane soon, so this post will be a bit more stream of conscience and off the cuff. I want to articulate some perhaps half-baked, but educated thoughts on if we are hitting the scaling law limit on AI model development, what this plateauing could potentially mean for the intensifying US-China AI competition.
There has been a flurry of reporting over the last week from The Information, Reuters, and Bloomberg on leading AI labs – OpenAI, Anthropic, DeepMind – all starting to see diminishing returns in a model’s capabilities, as they scale up their compute power and data volume to train their next generation foundation models. Marc Andreessen and Ben Horowitz also shared similar doubts in an a16z podcast episode. The big question that these reports raise, if true, is are we hitting a limit on the so-called “scaling law”.
In plain language, the "scaling law” is an observation that when you increase the compute and data devoted to training a model with more parameters, that model’s capabilities improve proportionally to those increases. In a nutshell, bigger the better. Hitting diminishing returns on the scaling law does not mean the new model in-training is not improving, but the magnitude of improvement does not match up with the amount of cost (compute, data, power) spent on the training.
Just like Moore’s Law (the number of transistors on an integrated circuit doubles every two years), the scaling law is not a law of nature. It is not really a law at all. It is an empirical observation that can be true for a while, and thus guide the direction of technological innovation for a while, until it stops being true.
If, and still a big if, we are getting close to the limit of the scaling law, this could have major implications to how the US-China AI competition could shape up in the next few years.

Export Control Becomes Less Effective
As I’ve written previously, I anticipate the US-China AI gap to widen by 2026, when Nvidia’s Blackwell GPU product line hits the global market in volume. This is, of course, global market ex China, because US export control has barred advanced GPUs like Nvidia’s Blackwell and Hopper, and similar analogous product lines from AMD and Intel from selling to China. The justification for this type of export control is to prevent China from advancing in AI.
In my assessment, the policy is effective enough in keeping Chinese AI development reliably 1-2 years behind America’s, in large part because having the most advanced GPUs at scale gives an AI lab the most advantage in the pre-training phase. After all, the P in GPT stands for “pre-trained”.
However, if scaling up no longer yields enough improvement to justify the magnitude of scaling, then the chokehold effect of not having access to the most advanced GPUs withers away – diminishing by roughly the same pace as the diminishing scaling law itself. This does not mean export control will be rendered ineffective overnight, just less effective over time.
Two months ago, when OpenAI released its o1 series, the Strawberry “thinking” model, where the model takes a longer time to “think” (as in search through its pre-trained universe to reason about the question) before it spits out an answer, all signs are pointing to more demand for inference workload, less on strictly training workload.
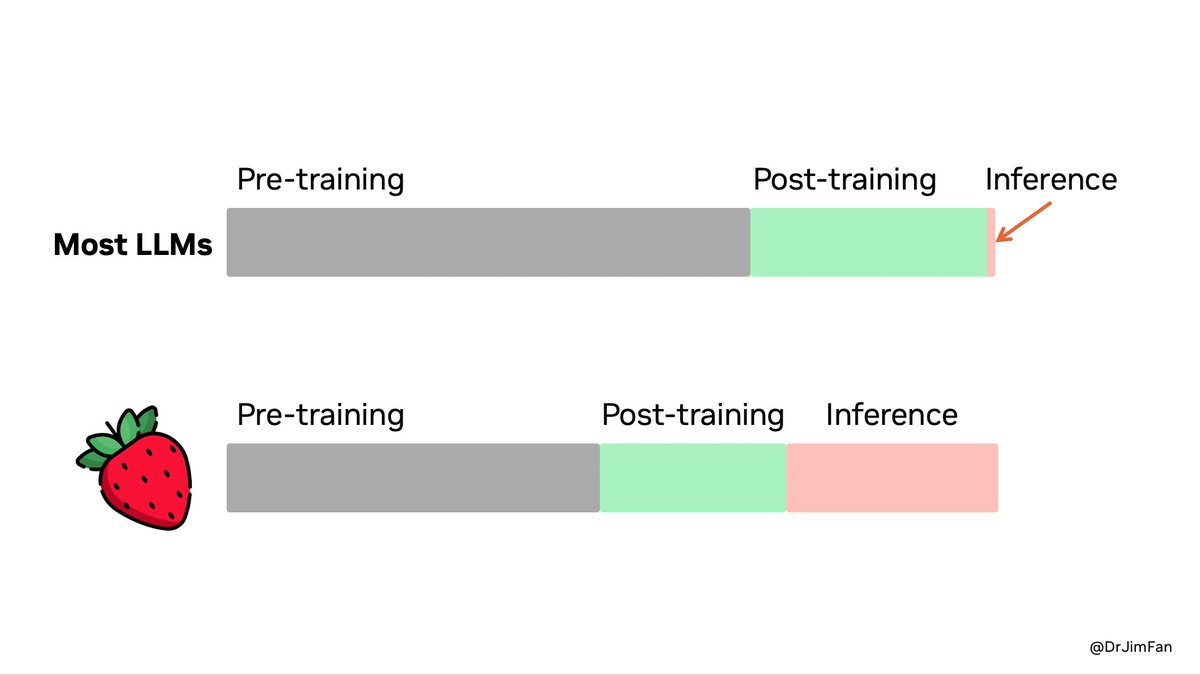
Even if only the training part of the scaling law diminishes, while the inference part continues to scale, the logical conclusion would be that the most advanced GPUs designed for powerful training would become less important over time. This trend favors China.
AI Doomsday Less Likely
One second-order conclusion of the scaling law is that larger data center infrastructure with more GPUs, more power, and more data will lead humanity to the promised land of building AGI. This AGI, which has superhuman intelligence and can self-improve to become more powerful over time, would be bad if it falls into the wrong hands (terrorist organizations) or built by the “wrong” country with the wrong ideology (China is the country most often used as the example). These scenarios lead to an unimaginable AI doomsday that could end humanity.
This “scaling law to AGI to doomsday” narrative has given fuel to many initiatives in the US, including the technology export control I just mentioned, but also more investment in nuclear power, less regulation for building power capacity, and fledgling government-led data sharing schemes to provide quality data to train America’s AGI before a foreign adversary does. The latest iteration of this narrative is a so-called “democratic AI vs autocratic AI” showdown, articulated by Chris Lehane of OpenAI calling on the US government to directly support a massive build out of energy and networking infrastructure to support building the supercomputer data centers necessary to get to AGI before China does. He also advocated for a “North American Compact” of western democratic countries to work together to build this “democratic AI” to counteract a possible autocratic version. (His whole presentation at the think tank, CSIS, is worth watching.)
However, if a diminishing scaling law shows that AI progression is not what it is all cracked up to be, then we may be much farther away from AGI than we think, thus all the doomsday scenarios that AGI would bring become more fantastical and less imminent.
Logically, this outcome would also cool the temperature down a bit in this zero-sum, US-China AI competition, if not only temporarily, as the entire AI research field globally looks for the next technique beyond scaling.
There are signs of this happening already. Ilya Sutskever, who was the first proponent of the scaling law when he was at OpenAI, has publicly shared his observation that the benefit of scaling up the pre-training phase is plateauing, as the research community returns to “the age of wonder and discovery once again [where] everyone is looking for the next thing”, including his new startup, Safe Superintelligence.
Even if the scaling law hits a wall tomorrow, what has been distilled up to this point in the form of GPT-4, Claude, Gemini, Qwen, etc. are nothing to sneeze at. These models have already made leaps and bounds, reached college-level or above intelligence level in many domains, and we are still in the early days of making the best use out of these models to build useful applications or agents. This application-focused phase has to come to fruition in the next two years for the hundreds of billions of dollars allocated to building AI infrastructure, on the promise of the scaling law, to be worthwhile.
So far, the US is winning on both the advanced semiconductor layer and the foundation model layer. If the model layer stalls out while the semiconductor layer becomes less of an advantage, again both big if’s, then the competition moves to the application layer. Here, Chinese companies may have a small advantage.
That is at least the theory of the case promoted by Chinese AI startups, like Kai-fu Lee’s 01.ai. As Lee expounded in a recent podcast (in Chinese), his startup’s competitive advantage versus his American counterparts comes from Chinese engineers’ ability to work long hours on the grunt work of optimizing infrastructure to reduce inference cost, plus a richer talent pool of product managers, forged from the previous decade’s mobile Internet boom in China, to craft more useful and appealing AI applications.
The jury is still very much out on this theory, with or without scaling law.
Digging In
Whether the scaling law will persist or not is still a toss up question at the moment. But it is a question now and no longer a foregone conclusion.
I expect both sides of this debate will dig into their respective heels for next year or two, if only because so many promises have been made, and so much money has been spent on those promises. For a while, the leaders of both camps will talk past each other, at least publicly, to defend their respective narrative.
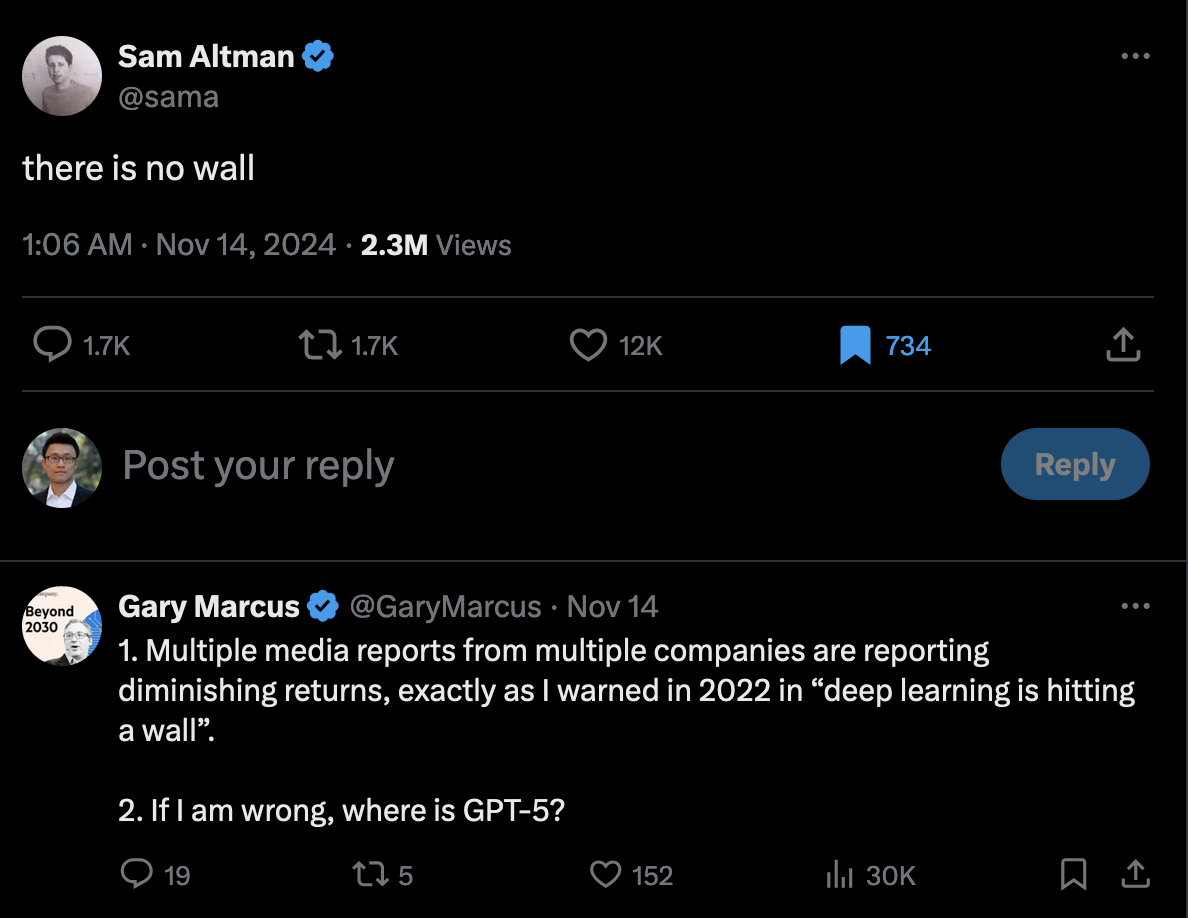
In classic fashion, Sam Altman cryptically tweeted a few days ago in response to all the scaling law doubters that “there is no wall”, only to draw a speedy reply from Gary Marcus, a leading AI hype critic, that he called the scaling law limitation two years ago in an “I told you so” tweet.
Dario Amodei, the CEO of Anthropic and probably the most nuanced and thoughtful AI startup leader in my view, told Lex Fridman on his podcast that he is “going to bet in favor of [the scaling law] continuing, but I’m not certain of that.” The hedging is telling, even though Amodei is likely still in the scaling law camp and has to be for a while to justify the $8.75 billion dollars Anthropic has raised so far.
This week, Nvidia’s earnings release and Microsoft's Ignite conference are both expected to push back against the scaling law limit narrative, if only because both companies have bet the farm on scaling law working. If it doesn’t, less customers will be interested in Nvidia's Blackwell product, which continues to experience issues, most recently in overheating. Microsoft, which plans to spend more than $100 billion on GPUs and data centers alone by 2027, will have to deal with a lot of “overcapacity” if scaling does not work out.
To be clear, scaling law hitting the limit soon is still a small probability event, but with asymmetrically large consequences. And the nice thing about fake laws like the scaling law is that it is less religion, more empirical, and cannot be easily deluded away – it either works or it doesn’t.