
Today’s post is a guest contribution from Shawn Xu (no relations). Shawn is one of the early engineers at Ascend.io, got his Masters in Human Computer Interaction at Carnegie Mellon, and writes an informative WeChat public account on SaaS called 硅谷成长攻略.
(The audio version of this post can be found on the Interconnected YouTube channel):
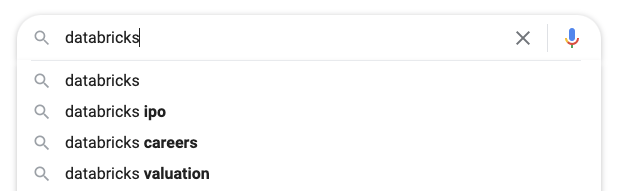
Type "Databricks" into Google and you'll likely see the first few suggested entries being "ipo", "careers", and "valuation". That's enough to suggest the massive hype around this Big Data unicorn -- the same kind of hype seen with Robinhood recently, or a few years back with Uber and Airbnb.
However, unlike the sharing economy and fintech, Databrick's products and core business remain known to only a small community of VCs, data scientists, and nerdy engineers like me.
This article serves to help more people -- engineer or not -- navigate Databricks, a relatively lowkey unicorn. To do that, I won’t jump straight into the technical weeds of Spark and Delta, but will instead begin with a high-level view of the broader Big Data landscape to explain how Databricks fits into the big picture and where it's headed.
Big Data Landscape in 30 Seconds
While the Big Data market is a $100B+ dollar beast with double-digit year-over-year growth, it really boils down to three key questions, two fundamental concepts, and one common goal (or the holy grail).
Three questions:
- What is the data? (systems-generated data, commercial data, user data, etc.)
- What to do with the data? (business intelligence, analytics, machine learning, dashboarding, etc.)
- How to move data from A to B? (ETL (Extract, Transform, Load) and its many variants)
The answer to each question has room for a dozen different solutions. Each solution has enough market demand and commercial interest to support numerous public companies.
Two fundamentals:
- Storage (data persisted to a physical disk, either on-premise, or in the cloud)
- Compute (renting a server to perform some computational tasks on the stored data)
Compute is usually where most of the money is spent, meaning that keeping servers up and running is significantly more expensive than allocating physical space on disks to store data. There are also other areas of spending like networking, but that’s less relevant in our discussion about Databricks and Big Data. (For a full explanation of how storage, compute, and networking work together, see Kevin Xu’s earlier post: “How To Tax Cloud Computing?”)
One Holy Grail
The one common goal that every company wants to achieve with their data is: an automated journey that takes raw datasets and turns them into business value.
In the pre-web days, when most of our data could sit comfortably in Excel spreadsheets, this was easy: deploying a VBScript with several functions would suffice. Now, we are drowning in a gazillion YouTube video watch events -- start, pause, skip ads, etc. -- being collected, parsed, aggregated, and eventually turned into one single dashboard. And all this happens on an hourly basis.
A Thousand Paths
While the end goal is common, there are (literally) a thousand paths to reach this holy grail. Every SaaS or open source company operating in the Big Data domain falls into one or many parts of this “data journey”. While the cloud giants (AWS, Azure, GCP) are all attempting to build an all-in-one service, there's plenty of room for smaller vendors with creative solutions to find a foothold, grow, and become a giant themselves. Databricks is one of these examples.
To appreciate how vast the Big Data landscape has grown to become, I find Matt Turck's landscape graphic (updated yearly) quite handy. Over just the last few years, not only has the number of companies in each category grown, but new clusters of solutions are also popping up to form sub-categories.
So, what does Databricks do?
If you're confused by the tagline on Databricks's homepage ("All your data, analytics and AI on one Lakehouse platform"), you are not alone. But with the big picture I just laid out in mind, let’s see if we can make some sense out of this tagline and the company itself.
In essence, Databricks is a compute company that presents a low-code solution to pursue the holy grail by answering the two of the three key questions:
- What to do with the data?
- How to move data from A to B?
Why does answering these two questions make Databricks a valuable company? An analogy that may help illustrate this point is the more well-known example of Arduino, an open source electronic prototyping platform.
Imagine you are tasked to build an FM radio with a bunch of electronic components. It's daunting, at least if you are like me, with little hands-on hardware building experience.

That daunting feeling is what engineers feel when building the “data journey” with barebone software components: renting virtual machines from AWS and writing Python scripts to compute on some datasets. You'll soon run into roadblocks like: how to coordinate multiple machines to parallelize the process, how to handle machines that go rogue and lose connection, etc.
Arduino made prototyping and building digital devices easy. Instead of starting from switches and circuit breakers, the platform provided three important offerings to appeal to non-hardware engineers:
- A higher-level language that packages up useful functions to control the Arduino board. (For example, simple tasks like reading from a digital pin would take a non-trivial amount of C/C++ coding, but in Arduino it’s just a single function call: digitalRead(pin).)
- An ecosystem based on breadboards, where modules can be easily pushed into the sockets to facilitate rapid prototyping.
- A feasible path from turning Aruidno prototypes into production-ready hardware.

If you think Arduino’s platform is powerful, then it’s not hard to see how Databricks is also powerful, because it also offers three core building blocks, but for Big Data:
- Apache Spark: an open source engine abstracting away the complexity of working with distributed computing. Spark makes the task of taking one petabyte of data stored in 1,000 machines and multiplying a column of each individual record by 2, while at the same time staying resilient to random machine outages, as simple as a single command: .map(lambda x: x * 2). This command is the same as if you were to do the same task on a single machine. Spark handles all the underlying complexities and only surfaces the higher-level functions, packaged in Python, Scala, and SQL.
The founders of Databricks, a bunch of “Berkeley hippies”, as CEO Ali Ghodsi calls themselves, were the original creators of Spark. These “hippies” live and breathe distributed computing.
- Notebooks: a plug-and-play environment to prototype with data. Consider Notebooks as the breadboards -- an interface to get quick feedback when working with unfamiliar datasets. Each “cell” in a Notebook can run a few lines of code and show results instantly, much like an inserted Arduino component that performs some tasks.
Notebooks are not unique to Databricks; it’s a common interface to many data scientists and analysts. Jupyter Notebook is another popular solution. Yet, when Spark is combined with Databricks’s Notebooks, a data scientist gets superpower. These Notebooks, by default, are connected to an enormous amount of distributed computing power via Spark, thus can run calculations on really big datasets -- something a single machine cannot achieve.
As it turns out, connecting Notebook to underlying computing resources at scale is a non-trivial engineering workload. It’s the type of work that Databricks’s core users, mostly data scientists and analysts, find boring and burdensome. In many companies, these are the same people, who are in charge of discovering the data “holy grail”! Much like people who use Arduino, they rarely have a complete design in mind to begin with. Their work is a lot of prototyping and trial and error, whether it's cleaning the data or training a machine learning model. Databricks comes in at the right moment to provide them with the familiar Notebook interface, plus the distributed computing “superpower” to make working with Big Data easy.
You may recall my earlier post on Low Code No Code and the core value proposition of these products: freeing engineers from low-impact programming. Databricks tells a perfect low-code story with its plug-and-play Notebook offering for data scientists and analysts.
- Jobs: a pathway from development to production. So we have a dozen Notebook cells prototyped and functioning. What now? We don't want to manually run each cell whenever there is new data coming in. Also to bring down prototyping cost, we typically only bring in a subset of data to work against, not the entire dataset.
Databricks takes a genius approach by offering a feature called "Job". A “job” grabs a working Notebook and runs it on a user-defined schedule with an auto-scaling mechanism, so it can work with the full dataset in production.
This significantly cuts down the time required to take a working prototype from development to production. The power of Spark really comes into play here -- the same code can seamlessly transition from handling a few gigabytes of data on a few machines to processing many petabytes of data across thousands of machines.
How Does Databricks Make Money?
Like I mentioned, Databricks is a compute company. Like other companies in the category, it makes money by keeping servers up for customers.
It is worth noting that Databricks does not own any of these servers. Instead, the whole system is built upon the infrastructure of the major cloud providers (AWS, Azure, GCP). For Databricks users, their bills largely break down into two parts: the cost of keeping these machines up and running (charged by the underlying cloud provider), and the "add-on" functionalities like Notebooks and Jobs that Databricks provide on top of these machines. Both types of costs are charged on an hourly basis -- a strictly pay-as-you-go model.
Databricks is not the only company building on the shoulders of the “cloud giants”. The other well-known player and fierce competitor of Databricks, Snowflake, also employs a similar approach. Snowflake’s easy-to-use cloud data warehouse is backed by the same set of cloud infrastructure building blocks.
Is it possible for capable engineers to use the same building blocks, like AWS EC2 and S3, to build an in-house version of Databricks to reduce cost?
Certainly possible, but likely not worth it, at least not until this company reaches a certain scale. Going back to our all-code vs low-code discussion, just because you could build something doesn't mean you should. Databricks offers features like cluster auto-hibernation, sharing, and permission management to convince users that paying Databricks is better money spent than devoting engineering hours to build and maintain something similar in-house.
"All your data, analytics and AI on one Lakehouse platform"
By now, I hope this tagline is starting to make a bit more sense. Databricks is basically trying to own the entire “data journey”, which means more data, more machines, more servers to keep running, and more money for the company. Of course, Databricks customers get value by not having to do any of this work themselves.
Looking at Databricks's roadmap, it isn't hard to notice its ambition to expand beyond just a "Notebook" company (which many people consider it to be right now).
While data scientists and analysts love Notebooks and don’t mind paying the "low-code premium", data engineers are a different breed. They work closer to the data sources and are responsible for data ingestion, maintaining infrastructure, and performance tuning. These engineers value flexibility and don’t mind writing some extra code to get the job done the way they like it.
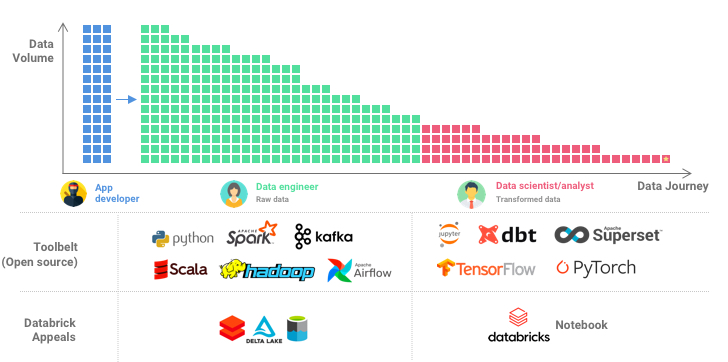
Data engineers work on the earlier phases of the “data journey”, which also happen to be compute-intensive and costly (in other words, a good source of revenue). To win them over, Databricks's solution is to invest more in open source, namely by introducing Delta Lake (where Lakehouse comes from), an open source storage layer. Open-sourcing gives these engineers the much needed flexibility to exert control over data governance, movement, and reliability. And while anyone can use the ".delta" format with any solution, not just Databricks’s solution, it is supported out of the box in Databricks Notebooks. Combining that with features like "Live Table", the whole platform seeks to win over even the most hardcore data engineers by providing observability and tunability.
In the long run, getting all the data personas -- engineers, scientists, analysts -- working on the same platform is tremendously valuable in obtaining the data “holy grail”. The shared context, visibility, and collaboration lead to more agile organizations and faster product lifecycles.
Databricks wants all these personas to live in the same “Lakehouse”. It’s not quite there yet. It’s still building this “house”. But for an eight-year-old company, it’s making impressive progress.
To read all previous posts, please check out the Archive section. New content will be delivered to your inbox once a week. Follow and interact with me on: Twitter, LinkedIn, Clubhouse (@kevinsxu).
Databricks是做什么的?
今天的文章是徐晟洋(和我没有亲戚关系,纯属凑巧哈)写的《互联》的“嘉宾专栏”。他是创业公司Ascend.io的早期工程师之一,在卡内基梅隆大学获得了人机交互的硕士学位,并写一个与SaaS行业有关的干货很足的微信公众号《硅谷成长攻略》。

在Google 中输入“Databricks”,看到的前几个建议条目很可能是“ipo”、“工作机会”和“估值”。 这足以表明大家对这个大数据独角兽的十足兴趣——如同科技圈对这几年的Robinhood、几年前的Uber和 Airbnb广泛的热情。
然而,与共享经济和金融科技不同,Databrick的产品和核心业务,仍然只有一小部分的VC、数据科学家和工程师有所了解。
这篇文章旨在帮助更多的人——无论是不是业内人士——理解Databricks,这个相对低调的独角兽。 因此,我不会上来对Spark和Delta之类的技术大聊特聊,而是先快速的纵览大数据这个独特领域,再解释Databricks是如何融入其中,前景又如何。
30秒的“大数据”概述
尽管大数据市场十分庞大,是一个千亿美元、年同比增长达两位数的吸金兽,但它最终归结为三个关键问题、两个基础和一个终极目标。
三个关键问题
- 要处理什么数据? (系统生成的日志,或是商用数据集,或是用户数据,等等)
- 如何使用数据? (商业智能BI,商业分析,机器学习,图表,等等)
- 如何把数据从源头向下游汇集和转化? (ETL数据管道,以及各类变种)
这三个问题,每个问题的答案都有十几种不同的解决方案。而每个解决方案都有足够的市场需求,来容纳多个优质上市公司。
两个基础:
- 存储(数据存放在物理磁盘上。无论是在本地的数据中心里,还是云上)
- 计算(租用一个服务器来对数据进行计算)
计算是花销巨头,原因是,服务器的运行(按时间计算)比为磁盘的占地(空间)昂贵得多。当然,完整的来说,网络也是基础之一,但与这篇Databricks的讨论相关度不大。 (关于存储、计算和网络如何协同工作,请参阅Kevin Xu之前的帖子:“如何对云计算征税?”)
终极目标
每家拥有数据的公司,希望实现的一个终极目标是:搭建一个自动化系统,将原始数据集源源不断地转化为业务价值。换句话说,一个自动将“数据变现”的系统。
在互联网风靡之前,我们的大部分数据还保存在 Excel 电子表格中时,这并不难:写几个VBScript就足够了。 现在,我们的每一个YouTube视频观看事件——开始、暂停、跳过广告等,都被收集、解析、聚合,最终变成某个高管屏幕前的柱状图。 而这一切,很可能时刻都在发生。
殊途同归
虽然最终目标类似,但有可以实现的方式却十分之多。每个在大数据领域运营的 SaaS 或开源公司,都致力于这条“数据流水线”的一个或多个部分。 虽然云巨头(AWS、Azure、GCP)在尝试构建一体化的服务和生态,但拥有创造性解决方案的小型供应商仍有足够的空间找到立足点,并成长并成为巨头。 Databricks、Snowflake就是典型的例子。
如果想了解当今的大数据领域是怎样一个庞然大物,Matt Turck的年度大数据版图很有参考价值。 在过去的几年里,不仅每个类别里的公司数量都有所增长,新的类别也在不断涌现。
话说回来,Databricks到底是做什么的?
如果你对Databricks官方主页上的标语(“一个 Lakehouse 平台,承载所有数据、分析和人工智能”)感到困惑,那你一定不是唯一一个。 但有了上面的概述,让我们看看能否从这个标语得到一些启发,来了解Databricks。
从本质上讲,Databricks是一家计算公司,通过解决三个关键问题中的以下两个,提出了一种搭建数据流水线的低代码解决方案:
- 如何使用数据?
- 如何把数据从源头向下游汇集和转化?
为什么解决这两个问题,会让Databricks变得如此有价值?一个有帮助的类比,是更知名的Arduino——一个开源的电子原型开发平台。
想象一下,如果你被派了一个任务,要用一堆电子元件搭一个FM收音机——如果你和我一样,几乎没有任何硬件方面的经验,这听上去根本无从下手。
这种无从下手的感觉,正是许多工程师在使用低抽象工具构建“数据流水线”时所感受到的:从AWS云服务租用虚拟机,编写Python脚本,对数据集进行计算。不一会儿,困难就会接踵而至:如何协调多台机器使得计算能够并行?一个虚拟机计算了大半,突然断线了,怎么处理?
回到Arduino,之所以它使得原型设计、构建变得如此容易,归根究底,是因为其并没有从开关、断路器这些基础元件出发,而是提供了三个重要的组件,来吸引你我一样的非硬件工程师:
- 一种更容易调度Arduino硬件的高抽象语言。(比如,基本如“从一个数据针读取数据”的简单操作,用C或者C++写,工作量不小。而在Arduino平台上,这只用调用一个函数digitalRead(pin)就行了)。
- 一个架构在面包板上的硬件生态,每一个模块都可以毫不费力地插入拔出,方便快速迭代。
- 一套可行的、从Arduino原型到可售卖版本的转化流程。
假如你认同Arduino为硬件开发带来的革新,那么Databricks的作用很好理解——它同样带来了三个核心组件,只不过是针对大数据运算:
- Apache Spark:一个开源引擎,通过高抽象语言,极大地降低了分布式计算的门槛。设想一下,现在我们手头有1个PB的数据,分布在1000个机器组成的集群上,现在需要把每条数据里的某个值乘以2,并且处理好过程中任何机器断线造成的结果丢失。用Spark的Python接口来写,只需要一行:.map(lambda x: x*2)。这和在单个机器上对一个数组进行操作完全一样——这种便利背后,Spark包装了所有与机器集群打交道的复杂度,让用户可以用他们熟悉的Python、Scala、SQL语言发布命令。
Databricks的创始人们——用CEO Ali Ghodsi的自嘲来说,一群“伯克利嬉皮士”——是Spark框架的始作俑者。这些大数据嬉皮士们在分布式计算世界里是举足轻重的人物。
- 数据笔记本:一个即时交互、反馈迅速的数据沙盒。把这个笔记本想象成Arduino的面包板,插上不同的组件,可以快速获得功能上的反馈。在数据笔记本中,用户可以在每一个“单元格”里跑几行代码,实现一个小功能,并实时给出计算结果。
数据笔记本并不是Databricks特有的功能。事实上,这是数据科学家和分析师最常用的工具之一,Jupyter Notebook可以说是最早、最知名的提供商。然而,Spark使得Databricks的数据笔记本获得了超能力:每一个数据笔记本都可以连接上数量巨大的服务器集群,并且通过Spark对大量数据做并行计算。这是单个机器上的数据笔记本远远无法达到的。
从工程上来说,将数据笔记本对接上大量的计算资源,并不是那么容易的事。这也是Databricks的主要用户们(数据工程师和分析师)厌于完成的繁杂工序。
在许多公司里,这些人肩负着达成“最终目标”的使命,而他们正如同Arduino的使用者一样,在开始搭建数据流水线时,需要不断地试错、迭代,无论是清洗数据,还是训练一个机器学习模型。Databricks在合适的时机出现,通过这个获得了超能力的笔记本,让搭建过程变得十分便捷、迅速。
如果读过我之前一篇“无代码、低代码”文章,你或许记得低代码产品的核心价值:将工程师们从低价值的劳动中解放出来。Databricks通过这个上手即用、高抽象的数据笔记本,很好地阐述了这样一个低代码故事。
- 任务集:从开发到生产的无缝衔接。现在我们有一个笔记本,其中包含一堆单元格,实现了一个初步的数据流水线,接下来呢?我们自然不想每次有新的数据进来,都需要手动地一个个单元格跑一遍。另外,在开发过程中,为了加快运算速度和降低成本,我们一般只会采用数据集的部分(一个样本),而非整个数据集。
Databricks的解决方案,“任务集”,非常方便:每一个任务对应着一个笔记本(实现着一个完整功能),用户们可以指定运行频率、机器数量上限,每隔一段时间自动运行笔记本中的所有单元格,完成对完整数据集的计算。
对已经有一个基于笔记本的流水线来说,从开发环境到生产环境,几乎只需要按几个按钮。这全都仰仗于Spark带来的便利:无论是几个机器上1GB的数据,还是几千机器上数十PB的数据,跑的都是同样一套代码,几乎无需变动。
Databricks如何赚钱?
归根究底,Databricks 是一家提供“计算”的公司。 与该类别的其他公司一样,它通过租出服务器的计算资源来赚钱。
值得注意的是,Databricks并不真的拥有这些服务器。 相反,其整个系统建立在主要的云提供商的基础服务上(AWS、Azure、GCP)。 对Databricks用户来说,他们的账单主要分为两部分:常规的服务器租用成本(由底层云提供商收取),以及Databricks在这些服务器上“附加”的功能费用,如数据笔记本和任务集。 这两个成本都是按小时收费的——常见的按用量收费方式。
Databricks并不是唯一一家站在“云巨头”肩膀上的公司。他们的另一位知名竞争对手,Snowflake,也采用了类似的架构。Snowflake好用的云数据仓库,底层所依赖的基础服务,与Databricks非常相似。
那么,工程师们是否可以使用相同的构建模块(例如 AWS EC2 和 S3),来自己搭一个“内部版本的Databricks”,来避免给Databricks交钱,降低成本?
当然可能——但很可能不值得。至少,在这家公司达到一定规模之前都不值得。回到我们关于全代码、低代码的讨论,“可以做”不代表“应该做”。Databricks提供的集群自动休眠、共享和权限管理等功能,都需要很多工程资源来搭建,而这些工程资源,可以用到对一个公司更有价值、更核心的地方。
"一个Lakehouse平台,承载所有数据、分析和人工智能"
读到现在,希望这个标语开始变得更有意义一些(除了Lakehouse部分)。Databricks试图提供完整的“数据流水线”方案——这意味着更多需要处理的数据、更多跑数据的机器、更多的收入。当然,Databricks的用户愿意为平台的解放出来的生产力付费。
Databricks的产品规划,很清晰地告诉我们,它不想局限于一家提供“数据笔记本”的公司(这是很多人现在的认识)。
这是因为,尽管数据科学家和分析师们喜欢这些强大的数据笔记本,不介意为之付出“低代码溢价”,数据工程师们却并不总这么想。他们的工作更底层,负责数据接入、基础架构、效率提升。这些工程师们对灵活度的要求很高,并且完全不介意多写一些代码,或是自己搭方案。
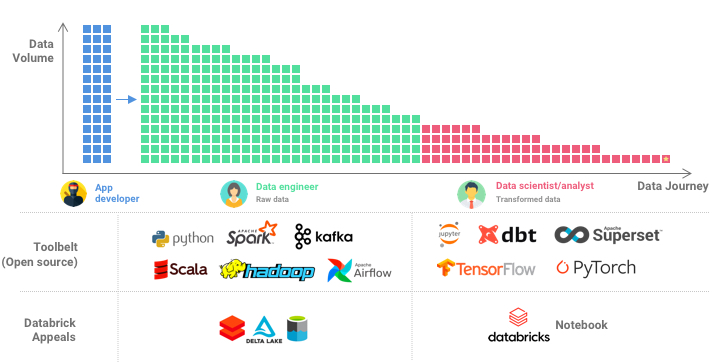
在“数据流水线”上,这些数据工程师们往往占据上游,也是运算量、成本极大的一个环节(换句话说,重要的收入来源)。为了赢得他们的青睐,Databricks采用的策略是拥抱开源,尤其是即Spark之后,推出了Delta Lake——一个开源的数据存储方案(这也是Lakehouse的名字来源)。开源的方案给了这些工程师们所需的自由度,使得他们能够更可预期地掌握、挪动数据。Delta的开源,意味着任何人都可以在其方案里使用优秀的“.delta”存储格式,但是这在Databricks的数据本里,有着最为方便的原生支持。与新的功能,比如”Live Table“一起,Databricks平台已经开始赢得一些硬核数据工程师的青睐。
从长远来看,能让所有与数据打交道的人们(数据工程师、数据科学家、分析师)在同一个平台上协作,有着巨大的价值。每一方都可以有完整的视图、上下游语境,让开发”数据流水线“的过程快上许多。
Databricks想让这些人都住在同一幢”Lakehouse“里。任重而道远,工程仍是进行时。但对这家八岁的公司来说,进展迅速,未来可期。
如果您喜欢所读的内容,请用email订阅加入“互联”。要想读以前的文章,请查阅《互联档案》。每周一篇新文章送达您的邮箱。请在Twitter、LinkedIn、Clubhouse(@kevinsxu)上给个follow,和我交流互动!