
We are approaching the first anniversary of the “DeepSeek Moment” (January 27). Anticipation for DeepSeek to release a new, more powerful model before Chinese New Year (February 17) is running high.
High expectation almost guarantees reflexive disappointment. While I eagerly await this new model to learn what DeepSeek has been up to, I don’t anticipate it will shock the market the way it did a year ago. The entire AI industry and broader market has gotten used to more open weights models, especially ones produced by Chinese labs, being released every other month or so, with solid if not bleeding-edge performance. By virtue of being open and free, these models are gaining traction everywhere in ways that are impossible to trace and track – another virtue (or vice) of open source technology at large. The world's largest AI is still OpenAI in terms of token generation, but the second largest, as Jensen Huang likes to say, is open source AI.
DeepSeek may have fired the first shot in releasing V3 and R1 last year as the first permissively–licensed models (MIT License), but other labs quickly followed suit, from fellow Chinese competitors like Alibaba with its Qwen model series, to the gpt-oss model from OpenAI. (Both use the Apache 2.0 license, another common open source permissive license.) As I noted before, if it weren’t for DeepSeek, OpenAI would’ve never felt the pressure to pay more than some lip service to its open source root by releasing gpt-oss. While DeepSeek has continued to open source the weights of its models plus various tools and libraries, it is no longer the most open lab on the market either, because it never opened up its datasets or the main codebase it used to train its models.
Right now, the top three models in the world in terms of openness comes from NVIDIA (Nemotron 3), the Allen Institute (Olmo 3), and the Mohamed bin Zayed University of Artificial Intelligence (K2-V2), according to Artificial Analysis:
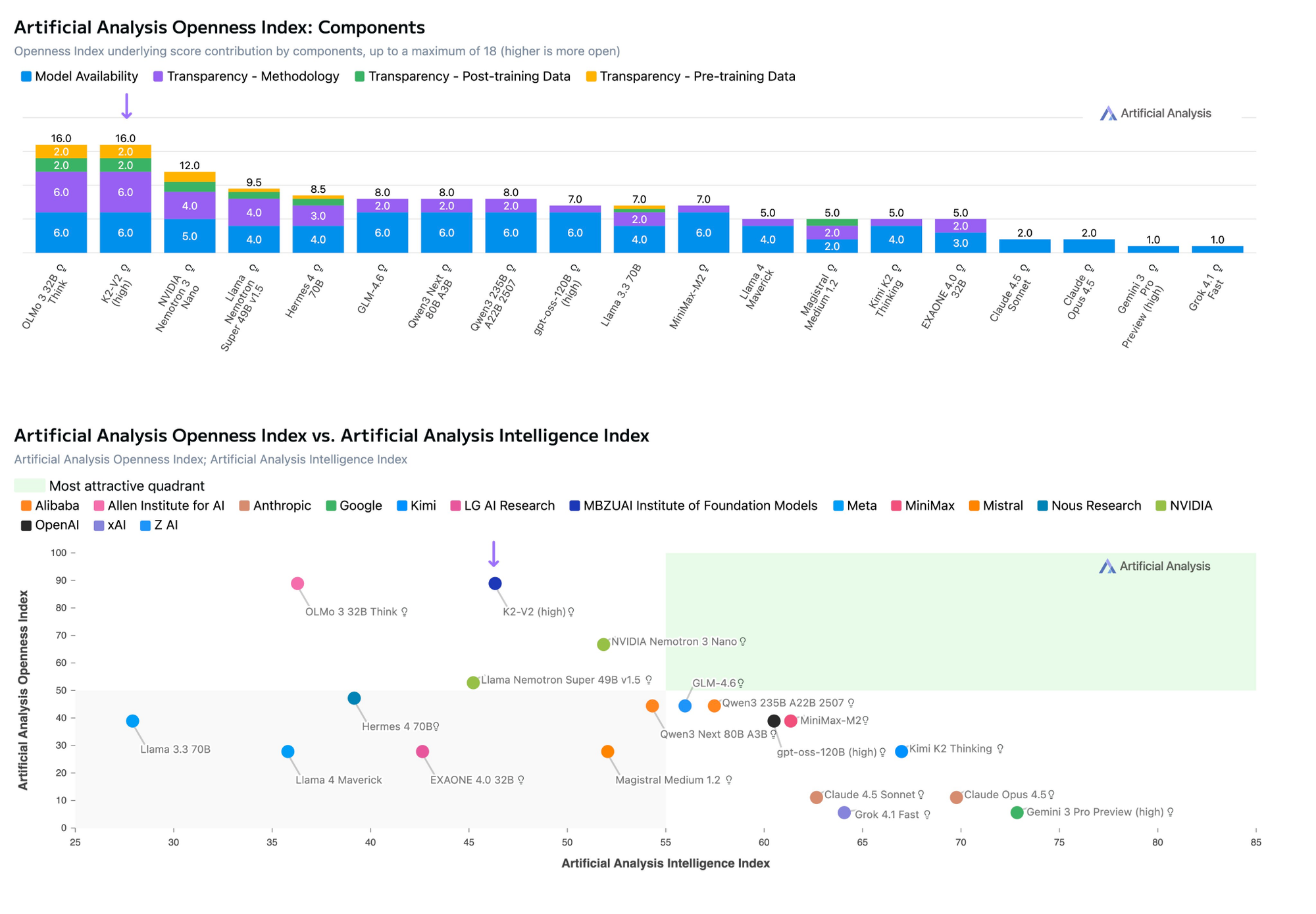
So DeepSeek’s models are no longer the most capable among open models, nor the cheapest, nor even the most open anymore. Is there a good reason still to give this lab which once shocked the world outsized attention?
Yes, I think so. But not because of its models or technological progress, but because of its internal incentives and business model. More precisely, we should pay attention to DeepSeek because it has no business model – a unique and counterintuitive feature (not bug) among all frontier labs in China, the US, and elsewhere.

Self Funding the AGI Dream
I mentioned this “no business model advantage” when I first wrote about DeepSeek a few weeks before it had its "moment" and became a household name. (Also podcasted about it then on ChinaTalk.) What’s notable is how stubbornly enduring this advantage has been, when the entire AI world is drowning in capital.
Liang Wenfeng has raised zero outside funding. The lab does generate some revenue from its API service but continues to reduce its pricing. Liang is content to fund DeepSeek R&D from the earnings of his quant fund, High Flyer Capital, that incubated DeepSeek initially. To be clear, Liang did try to raise VC funding from Chinese investors when he wanted to start DeepSeek in 2023, a few months after ChatGPT was launched. But his AGI-pilled idealism minus a business plan, and Chinese VCs’ famous short-sightedness and risk aversion, led to a failed fundraising effort that became a blessing in disguise.
As 2025 raced by, more AI advancements have been funded by even more money pouring in, as to not miss out on even more potential advancements. Every lab with even a modicum of traction raised more money, and with that more commercialization expectation down the line. A new group of so-called “AI neolabs” – VC funded pure research labs – cropped up, led by star researchers, like Thinking Machines Lab (Mira Murati), SSI (Ilya Suskevar), and AMI Labs (Yann LeCunn). Even xAI, the lab I used to compare DeepSeek most closely with given their similar lack of commercialization imperative, bent to the lure of outside capital. A few days ago, Elon Musk’s lab closed a $20 billion Series E round with a mix of equity and debt.
Even one of the richest men in the world couldn’t say “no” to more money! Meanwhile Liang Wenfeng continues to self-fund his secretive shop and his AGI dream. It certainly helps that Liang’s quant fund had a banner year last year, generating more than $700 million in profit on a 53% return. Presumably, most of that profit was poured into buying more GPUs (however it can in light of US export controls) and hiring talent to keep pushing DeepSeek’s research roadmap forward. Still raising a billion or two to accelerate its pace would have been trivial, after DeepSeek achieved worldwide notoriety and 100% brand recognition in the AI industry. Whether you love it or hate it, everyone has heard of it.
Yet, saying “no” to outside funding lets you control your destiny. And if your self-assigned destiny is “dedicated to making AGI a reality…unravel the mystery of AGI with curiosity…answer the essential question with long-termism” – DeepSeek’s tagline on its HuggingFace page – then less funding in exchange for total control is a worthy tradeoff. Of course, you could do some “corporate governance innovation” to get there too. This is the case at Thinking Machines Lab, where the founder’s single board vote is worth one more than the combined votes of all other board members, so effectively total control. But no matter how you “innovate” on the board level, the moment you take venture capital, large-scale commercialization to produce a venture-sized return is expected sooner or later.
DeepSeek has none of those expectations. Therefore, it has no business model and no need for a business model. The road to AGI requires compute, talent, and more than a healthy dose of good research taste. No one said it requires a business model.
More Money More Problem, No Money No Problem
Of course, the most common reason for raising more money is to buy more compute to support the research. However, it is not obvious that more compute is always necessary to produce good research.
This insight isn’t unique to DeepSeek’s idiosyncratic self-funded set up. llya Suskevar, who is arguably the AI researcher with the best research taste, also agrees. In his own words on the Dwarkesh podcast:
“Compute is large enough such that it’s not obvious that you need that much more compute to prove some idea. I’ll give you an analogy. AlexNet was built on two GPUs. That was the total amount of compute used for it. The transformer was built on 8 to 64 GPUs. No single transformer paper experiment used more than 64 GPUs of 2017, which would be like, what, two GPUs of today? The ResNet, right? You could argue that the o1 reasoning was not the most compute-heavy thing in the world.
So for research, you definitely need some amount of compute, but it’s far from obvious that you need the absolutely largest amount of compute ever for research.”
On the other hand, by removing the strings attached to outside funding and the necessity of buying more compute just because you have the money, two organizational benefits emerge. And DeepSeek has both.
First, there is no internal resource competition even though the resource is more limited. There is no bureaucracy, infighting, power struggle, and horse trading to determine whether the GPUs should support a new product launch, scale the inference demand of an existing popular service, or be allocated to a new research idea. Good research taste and new ideas can be maximally supported and embraced in a smaller lab with no outside funding and no business model, even if the total compute on an absolute level is limited.
Second, there is less jealousy and pecking order based on compensation, perks or how much compute your team gets versus another team, all of which would be toxic but ingrained in human nature. Your organization instantly becomes flat and can stay flat. With outside funding comes not only business model expectations but also valuation, stock options, and all the trappings of a richly-valued AI lab, however meaningless that valuation is in the early days. Paper wealth from fantastical valuation often gives way to an inflated sense of worth, envy, and poaching by even better funded competitors. The trappings become more than just about personal wealth creation, but are also tied to the brand, prestige, and appeal of the lab to lure more talent. And those trappings can get pretty ridiculous, like these “Thinking Machines” branded weight plates at the lab’s office gym:

Does DeepSeek have its own gym? I don’t know. Probably. But I’m pretty sure it doesn’t have branded plates. Does Suskevar wish he can self-fund SSI, which has raised $3 billion to date, just like Liang Wenfeng? Probably. He may have the best intuition and research taste, but he could not keep the poachers away – even his initial co-founding CEO was lured away by the deeper-pocketed Mark Zuckerberg of Meta. That isn’t to say DeepSeek is immune to poaching either. One of its star researchers, Luo Fuli, is now leading the AI effort for the deeper-pocketed Lei Jun of Xiaomi.
In an industry awashed in money, and the intrigues and dramas that money always brings, DeepSeek’s lack of business model thanks to zero outside funding is the source of its only enduring advantage: maximum internal alignment in service of AGI-bound research and nothing else.
I’m not even sure if I believe in AGI. But as an investor and a capitalist, I would love to get on DeepSeek’s cap table. That being said, if DeepSeek ever lets me or any outside investor in, what made DeepSeek DeepSeek would be ruined for good.