
This post is a collaboration with Howe Wang, who writes the ProcureFYI substack which is one of the best sources of alt data when it comes to US government procurement contracts and data center construction. I highly recommend his work!
Nvidia GTC wrapped up last week. CoreWeave’s IPO will price and start trading later this week. The generative AI industry is quickly moving from a “hopes and dreams” phase to a “rubber meets the road” phase.
A key group of players ushering in this major transition is the so-called “GPU clouds”, of which CoreWeave is their poster child (we discussed its S-1 here). Another GPU cloud that is rising quickly and already publicly listed is Nebius, a company with a fascinating history that we wrote a two-part deep dive on recently (Part I, Part II). Sure, there are other GPU clouds out there, but most of them are either still private companies or faking it while still mining BTC. CoreWeave and Nebius are the only two pure play GPU clouds that are (or soon will be) publicly traded.
There are many obvious, if not somewhat superficial, similarities between CoreWeave and Nebius. Instead of lazily harping on those similarities, what’s more useful is teasing out the materially meaningful differences between these two GPU clouds, so we don’t lump apples and oranges together and pretend they are both apples (or oranges).
That is what we will do in this post, fleshing out the key differences between CoreWeave and Nebius along three dimensions – core technology, customer base, and financial structure – and their tradeoffs. (For the goal of a clean comparison, we are ignoring Nebius’s other subsidiary properties, which you can read about in Part II of our previous deep dive.)

Blazing Fast GPU Scaling vs Full Stack Platform
CoreWeave’s core strategy is to be the first in line to bring the latest Nvidia GPU offering online as fast as possible and offer them at competitive prices via multi-year leases. This hardware-centric approach is evident in CoreWeave’s ability to rapidly deploy Nvidia’s Hopper and Blackwell GPU products as soon as they are available to the market, often within two weeks of receiving the full server plus GPUs from OEMs, like Dell and SuperMicro.
Because the CoreWeave founders are former energy arbitrageurs from the hedge fund world, they are experts in syncing up the complex logistics of procuring power, land, data center shells, and installing the GPU servers in record time for its customers to do AI training. The product offering, in essence, is quick and reliable access to bare metal GPUs in the tens of thousands, hundreds of thousands, and soon millions at a time. Because the offering is bare metal (i.e. not much software on top), the performance profile is blazing fast. This is highly desirable for their users, who are technically sophisticated and require immediate access to the fastest GPUs available for intense, large-scale AI workloads, such as training foundation models from scratch, but do not need the additional overhead of software services.
Nebius’s approach is broader and more full stack. On top of its own fleet of Hoppers and Blackwells are layers of software that you would normally see in an AWS or GCP, e.g. managed databases, MLOps services, container registries, and storage units. This strategy is a bet that the AI industry will need not only access to raw GPUs compute power, but also all the other table stakes features of a full-fledged cloud, in order to build useful applications in the long run.
Just like CoreWeave, Nebius’s differentiated strategy stems from its origin. Having emerged from Yandex’s divesture (more details in our Part I deep dive), Nebius inherited a "bare bones software stack" and a team of 500-plus engineers, many of whom built and operated Yandex Cloud. Collectively, this team has decades of experience building infrastructure and running cloud services for 3rd party customers. Nebius’s foundation in Yandex Cloud, with its strong software development expertise, naturally led to their strategy of abstracting the infrastructure layer to simplify developer experience, much like how CoreWeave’s energy expertise informed its strategy.
Because Nebius has built its own cloud from the ground up once before, it does not work with server OEMs like Dell and SuperMicro. It skips that step and designs its own server rack to build a more vertically-integrated system, by controlling everything from data center architecture to managed Kubernetes services to application-layer tools like Nebius AI Studio, which provides inference APIs for open weight models like DeepSeek, Llama, and Flux. (Here is a video of Nebius engineers presenting their in-house server design chops at an Open Compute Project conference.)
Tradeoffs: there is no single right way to build a GPU cloud. CoreWeave and Nebius's difference in approach shows that divergence and the requisite tradeoffs. You either start by offering a bare metal rental service that is fast and plentiful, or a more polished developer friendly stack that can do a lot of different things albeit with a less impressive performance profile.
That being said, cloud platforms tend to converge over time regardless of where in the stack they started from, because that is the only way to have staying power. We are seeing that from both CoreWeave and Nebius.
CoreWeave is starting to offer software layers like managed Kubernetes and Slurm via in-house development, as well as additional integration with external partners to provide inference services, like Together.ai and Fireworks AI. Its recent acquisition of Weights and Biases is geared towards accelerating those software services offerings too. Meanwhile, Nebius is flexing its server design muscle to drive more efficiency from its hardware components and not lose the TCO (total cost of ownership) competition to CoreWeave. As CoreWeave builds up the stack, Nebius is building down the stack, but both are doing so ultimately to expand beyond their initial customer appeal, which was dictated by how they chose to build their core technology offering.
Few Big Model Trainers vs Many Promising Application Startups
CoreWeave’s customer base targets a narrow but lucrative customer segment: large tech companies who train their own models. That’s why Microsoft accounted for 62% of 2024 revenue. That’s also why OpenAI signed a five-year, $11.9 billion deal with CoreWeave earlier this month. Its other marquee customer is no other than Nvidia. During its IPO roadshow, the company revealed that four of the six largest AI labs are customers.
CoreWeave is positioned as the go-to “training machine” for frontier model development. The bare metal service we discussed earlier is appealing because these frontier labs usually have the engineering talent to make the best use out of direct access to the GPUs without the software fluff on top. These customers need massive, homogeneous GPU clusters for training, not fine-tuning or inference, and have the in-house expertise to manage their own software stacks. They also have enough cash, or can raise enough cash, to fund long-term deals – something that CoreWeave must have in hand to build and procure more power and GPU capacity.
95% of the companies out there don’t want, or can’t make good use of, what CoreWeave is offering. But the 5% representing well-funded frontier AI labs really want it – a narrow but deep-pocketed niche.
Nebius’s customer cohort is less concentrated than CoreWeave’s. It comprises a mix of large AI training labs, startups, and enterprise in-house AI teams, but with shorter-term commitments. The makeup resembles AWS in its early days, which made up mostly early-stage startups who were more willing to try this thing called “the cloud”. The big bet was that one of these startups would become successful and “cloud-native”, which would bring in both more revenue and market validation that cloud computing was the new platform to build on. For AWS, that was Netflix.
Nebius is looking for and banking on the “Netflix of generative AI” to be born on its cloud. Thus, its more dispersed and diversified customer base makes sense. But so is everyone else. Luckily, using cloud computing is no longer a notion that needs to be validated. However, the competition for the next AI startup rocketship is as fierce as ever, both among the GPU clouds and with the hyperscalers.
Much of that is out of Nebius’s control. The only thing it can control, which is showing up in its core offering, is providing an end-to-end cloud that can be the “in-production inference platform”. We stress "in-production" because so much of AI right now is still in the R&D, experimentation, and proof-of-concept stage. Pre-training, which CoreWeave excels in, is by definition R&D. Deploying the fruit of that R&D into in-production services, where the bulk of inference workloads happen, is the next stage that Nebius is built to differentiate in.
Nebius’s customer base and services reflect this broader ambition. While it serves generative AI startups who train their own foundational models — mirroring CoreWeave’s core clients — it also brings on small or medium-sized developer and research teams within large enterprises. These customers, who are often not "pure tech companies" (e.g. logistic companies, manufacturing firms), would care more for Nebius’s full stack software abstractions, because they simply aren’t as technically capable as, say, OpenAI.
Tradeoffs: the difference in terms of customer types is rather stark. In CoreWeave's case, you have hyper-concentration but household names. In Nebius’s case, you have a wide dispersion, no recognizable names outside of tech circles, but more shots on goal.
Here is a breakdown of the two GPU clouds along all layers of the stack, based on publicly available information:

CoreWeave’s onboarding experience can feel a bit restrictive. New users must go through a “Request a Meeting” page and fill out a contact form to outline their needs. This curated access is uninviting for smaller teams or less experienced developers seeking an instant, self-serve setup. But for CoreWeave’s enterprise customers, who’ve already locked in large GPU allocations and know what they have access to, this process makes sense.
Through partnership, acquisition and some in-house development, CoreWeave is expanding what it offers to improve its developer experience. Its software stack now includes the CoreWeave Kubernetes Service (CKS) for scalable container orchestration, Slurm on Kubernetes (SUNK) for efficient workload scheduling, integrations with Weights & Biases for experiment tracking, and real-time observability tools for performance monitoring. This makes it an ideal platform for teams tackling large-scale machine learning and generative AI workloads.

Nebius delivers a streamlined, developer-friendly platform that simplifies AI training and inference through a fully-integrated, end-to-end environment. Most tools are developed in-house, including managed Kubernetes for scalable orchestration, Slurm-based clusters for efficient scheduling, MLflow for experiment tracking, proprietary observability tools, and a secure cloud platform for infrastructure control. Onboarding is seamless and self-served, with no upfront commitment required. A modest “free dollar” credit, paired with low token pricing (e.g., $0.02 per 1K input tokens and $0.06 per 1K output tokens for models like Meta Llama 3.1-8B-Instruct) is enough to do some experimentation. With AI Studio for fine-tuning and deployment, Nebius minimizes setup friction and offers a polished developer experience. This is ideal for teams looking to build, iterate, and scale quickly within a unified AI stack.
However, Nebius’s user experience is not without its challenges, particularly in after-sales support. Based on a customer interview, complaints include longer wait times for ticket resolutions compared to competitors like CoreWeave and Lambda Labs.

Because both types of customers have their strengths and weaknesses, the looming question is which GPU cloud’s model is more sustainable. And that gets to our last comparison of this post – financial structure – or debt vs cash.
Debt vs Cash
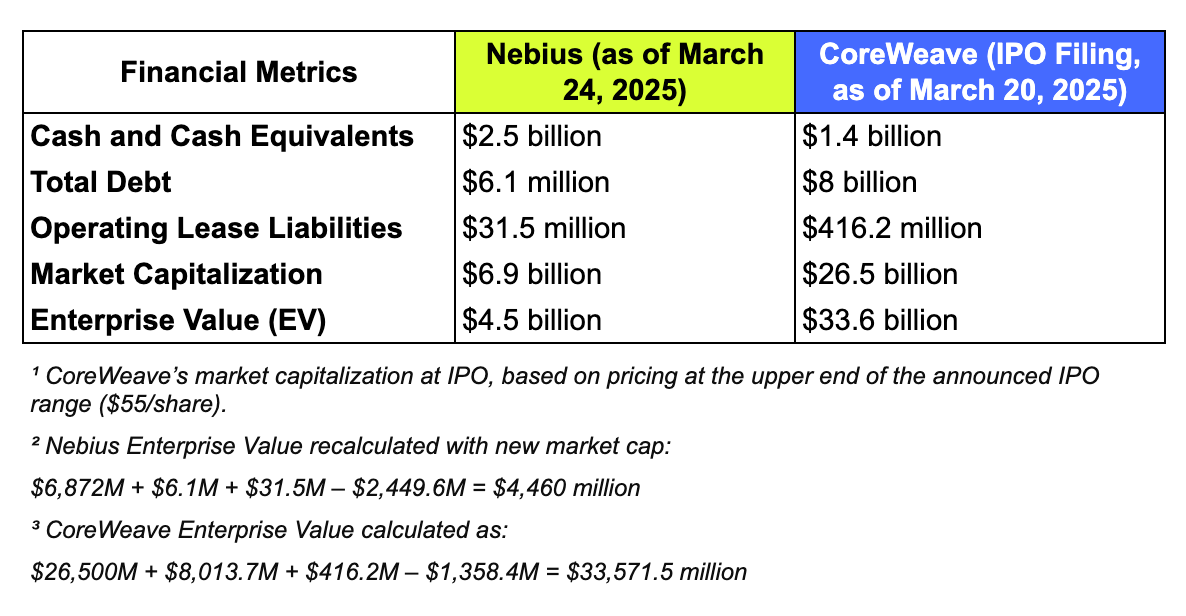
CoreWeave is pursuing a financial strategy marked by high leverage, something we discussed earlier. By the end of 2024, CoreWeave accumulated substantial total debt of approximately $8 billion, alongside significant operating lease liabilities of $416.2 million, while maintaining comparatively modest cash reserves of $1.4 billion. This aggressive financing structure is predominantly executed through specialized asset-backed debt facilities known as Delayed Draw Term Loans (DDTLs). CoreWeave notably does not directly carry most of the debt on its balance sheet. Instead, it utilizes Special Purpose Vehicles (SPVs) – separate legal entities issuing debt backed explicitly by tangible, revenue-generating assets such as GPUs, networking equipment, and data centers.
This sophisticated, asset-backed securitization model, while common in real estate and infrastructure sectors, is a novel approach in the cloud computing industry. CoreWeave’s approach offers tangible advantages, such as reduced risk for lenders through strong collateralization and potentially more favorable terms compared to traditional corporate debt or equity dilution. However, this approach also imposes significant constraints on CoreWeave’s operational flexibility. According to its S-1 filing, the company’s cash flows must prioritize servicing debt obligations, including considerable interest expenses, which reached approximately $361 million in 2024 alone. These obligations inherently limit CoreWeave’s ability to reinvest profits, fund additional growth initiatives, or expand infrastructure without more borrowing, let alone returning cash to shareholders someday.
A notably unique feature of CoreWeave’s financing model is its customer-linked variable interest rate structure, specifically within its DDTL facilities (DDTL 1.0 and DDTL 2.0 for customer contract CAPEX financing). Under this structure, CoreWeave’s cost of borrowing is directly tied to the creditworthiness of its customers. Contracts secured with investment-grade customers, such as Microsoft, carry relatively low interest rate spreads — approximately 6.5% above the SOFR (currently at 4.3%) or 5.5% above base rate loans. However, debt secured by revenue streams from non-investment-grade customers—including startups or emerging AI firms—commands significantly higher interest rates, up to 13.0% over SOFR or 12.0% over base rate loans.
If all these interest rates and loan terms are making your head spin, you are not alone. While complex, this model does align CoreWeave’s financing costs closely with the financial stability of its customer base, optimizing capital costs yet introducing variability and potential risk linked to customers’ financial health.
Nebius, in contrast, maintains a conservative capital structure with an easier to decipher balance sheet. It is buttressed by a substantial cash reserve of approximately $2.5 billion at the end of 2024, minimal total debt of only $6.1 million, and relatively low operating lease liabilities totaling $31.5 million. The cash came from the Yandex divestiture and the Nvidia/Accel investment. With its Nvidia-sponsored investment and historical relationship with Jensen’s team (Yandex was the largest Nvidia customer outside of the US and China during its heydays), Nebius will have preferential access to Nvidia’s newest products, e.g. Blackwell Ultra, and be able to bring them to market the quickest – just like CoreWeave.
This cash factor may not matter so much in the short-term, since all GPU clouds are still in land grabbing (literally) and market share growing mode. In that mode, unit economics and immediate profitability usually take a back seat. But in the long run, Nebius’s outright ownership of its AI infrastructure versus CoreWeave’s debt-fueled contract-collateralized “ownership” may prove to be the difference, as Nebius probably has a longer runway than CoreWeave to figure out positive, sustainable unit economics. The fact that Nebius’s power and infrastructure expansion plan, which is scheduled to increase 40x in two years, is funded out of its own pocket, not its creditors’, is something investors should keep in mind.
It is too early to know where the GPU cloud price war is going, though we observe that it is already underway. We are seeing Hopper GPU compute prices on the market hit estimated breakeven levels, based on our estimation of $1.6 per hour during the first year. (And every industry operator knows that sticker price is always subject to more bulk discount for large customers.) As Blackwell units flood the market, it will be crucial to watch how this new architecture holds up in terms of pricing power over the next 2–4 years.
One thing is certain: if all a GPU cloud offers is…GPUs, there is little differentiation between vendors, so a race to the bottom price war is inevitable. To survive and thrive in the long run, you must be able to offer the latest GPUs that the market desires early and build a truly differentiated software stack on top, in order to attract and keep developers from building somewhere else.
Is GPU Cloud All You Need?
In some sense, CoreWeave and Nebius don’t directly compete with each other. They are both racing ahead to fulfill a future paradigm dominated by Nvidia, where a room full of Jensen’s creations is all you need in a cloud data center. They are more friends than enemies, being simultaneously buoyed or sunk by Nvidia’s prospects.
If Nvidia fails, both GPU clouds will fail. Then again, if Nvidia fails, the whole “AI thing” along with half of the US stock market will collapse. We are not banking on that happening. And until we are proven wrong (and start hiding cash under our mattresses), the more productive exercise is still trying to answer: How do GPU clouds work? Where do clouds like CoreWeave and Nebius meaningfully differ? How do those differences help us project forward which one will do better in the future?
We hope this post answered at least some of those questions for you.